Parquet
Building the JDBC URL
After installing the license, open the connection management page by running java -jar kingswaysoft.jdbc.jar. Enter the required details to generate the JDBC connection URL. Click Test Connection to test the generated URL, or Copy to Clipboard to copy the connection string for use in your application.
Note: If the license is not installed, you can still use the connection manager to generate a JDBC URL; however, the 'Test Connection' feature will be disabled.
General Page
The General page allows you to specify connection properties and login credentials for the Parquet service.
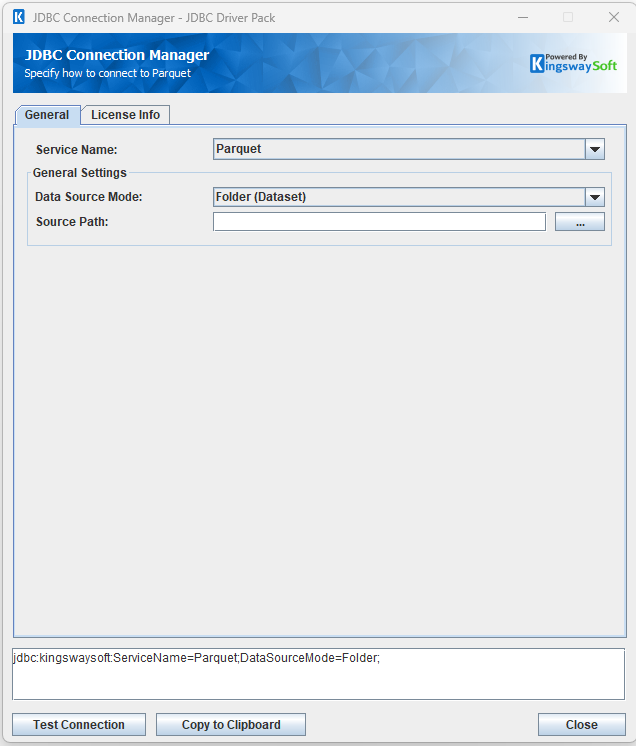
General Settings
- Data Source Mode
-
The Data Source Mode controls how logical table names are derived from the Source Path.
- Folder (default): subdirectory = table, multiple parquet files inside the subdirectory = the table's data set.
- File: parquet file = table, and the table name is derived from the file name without the parquet extension.
- Source Path
-
The Source Path specifies the local or network directory that the Parquet driver scans for tables.
- In Folder discovery mode, each immediate subdirectory is treated as one table.
- In File discovery mode, each immediate
.parquet,.snappy.parquet, or.gz.parquetfile is treated as one table.
Data Source Modes
The Parquet driver supports two data source modes through the DataSourceMode connection property.
Folder (Dataset)
Folder (Dataset) is the legacy and default behavior.
FolderPathpoints to a root directory that contains child directories.- Child directories should contain the Parquet files.
- Each immediate child directory becomes a table.
- All supported Parquet files within a child directory are merged into the same table.
Example:
D:\data
├─ customers
│ ├─ part-000.parquet
│ └─ part-001.parquet
└─ orders
└─ data.parquet
Tables exposed by JDBC:
customersorders
File Mode
File mode exposes immediate parquet files as logical tables.
FolderPathpoints to a root directory.- Each Parquet file located within the root directory becomes an individual table.
- The table name is derived from the file name by removing the Parquet extension.
Example:
D:\data ├─ customers.parquet ├─ orders.snappy.parquet └─ audit.gz.parquet
Tables exposed by JDBC:
customersordersaudit
If two files map to the same logical table name, the connection fails with a configuration error so the collision can be resolved explicitly.
Read and Write Behavior
SELECT
- In Folder (Dataset) mode, a table can read from multiple parquet files under its directory.
- In File mode, a table reads from a single backing parquet file.
INSERT
- In Folder (Dataset) mode, INSERT writes one or more new
part_*.parquetfiles under the table directory. - In File mode, INSERT creates or rewrites a single
<table>.parquetfile.
UPDATE and DELETE
- In Folder (Dataset) mode, only the parquet files that contain affected rows are rewritten.
- In File mode, the single backing parquet file is rewritten in place.
- If a DELETE removes the final row from a file-backed table, the backing parquet file is deleted.
WriteBatchSize
- In Folder (Dataset) mode,
WriteBatchSizecan split one INSERT into multiple parquet files. - In File mode,
WriteBatchSizedoes not create multiple files; the driver preserves the single-file table model and rewrites the same backing file.
Using the JDBC Driver
This section provides examples that use JDBC classes such as Connection, Statement, and ResultSet to manage interactions with Parquet data. It covers regular statements and prepared statements for complex or frequently executed queries.
Executing Statements
After you have connected from your code, you can execute SQL statements using the Statement class. For connection details, see Connecting with DriverManager or Connecting with DataSource. For parameterized statements, see Executing Prepared Statements.
SELECT
Use the Statement class's generic execute method or the executeQuery method to execute SQL statements that return data. To retrieve the results of a query, call the getResultSet method of the Statement.
String sql = "SELECT * FROM contacts"; try { ResultSet resultSet = statement.executeQuery(sql); LOGGER.info(resultSet.toString()); } catch (SQLException e) { LOGGER.severe(e.toString()); }
INSERT
Use either the generic execute method or the executeUpdate method of the Statement class to execute an INSERT operation.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the inserted data's ID, exceptions raised during execution, and details of the affected data.
String sql = "INSERT INTO emails (name, email_campaign_activities) VALUES ('testName5', '{ \"format_type\": 5, \"from_name\": \"Your Brand\", \"from_email\": \"[email protected]\", \"reply_to_email\": \"[email protected]\", \"subject\": \"Hello from API\", \"html_content\": \"<!doctype html><html><body><h1>Hello!</h1><p>API test.</p></body></html>\" }')"; try { statement.executeUpdate(sql); LOGGER.info(statement.getResultSet().toString()); } catch (SQLException e) { LOGGER.severe(e.toString()); }
id,errorcode,errormessage,processdata,haserrors
null,null,null,{"name":"testName5","email_campaign_activities":[{"format_type":5,"from_name":"Your Brand","from_email":"[email protected]","reply_to_email":"[email protected]","subject":"Hello from API","html_content":"<!doctype html><html><body><h1>Hello!</h1><p>API test.</p></body></html>"}]},false
UPDATE
Use either the generic execute method or the executeUpdate method of the Statement class to execute an UPDATE operation.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the updated data's ID, exceptions raised during execution, and details of the affected data.
String sql = "UPDATE contacts SET email_address.address = '[email protected]', update_source = 'Account' WHERE name = 'testName'"; try { statement.executeUpdate(sql); LOGGER.info(statement.getResultSet().toString()); } catch (SQLException e) { LOGGER.severe(e.toString()); }
id,errorcode,errormessage,processdata,haserrors
null,null,null,{"email_address":{"address":"[email protected]"},"update_source":"Account"},false
DELETE
Use either the generic execute method or the executeUpdate method of the Statement class to execute a DELETE operation.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the deleted data's ID, exceptions raised during execution, and details of the affected data.
String sql = "DELETE FROM contacts WHERE name = 'testName'"; try { statement.executeUpdate(sql); LOGGER.info(statement.getResultSet().toString()); } catch (SQLException e) { LOGGER.severe(e.toString()); }
id,errorcode,errormessage,processdata,haserrors null,null,null,null,false
USING OPTIONS for UPDATE and DELETE
When an UPDATE or DELETE statement matches more than one row in Parquet File mode, you can use USING OPTIONS to control how the driver handles the multiple matches.
Note: This option is supported only in Parquet File mode. It is not supported in Folder (Dataset).
Supported multiple match actions are:
| Option | Behavior |
|---|---|
All Matches |
Updates or deletes all matched rows. This is the default behavior when no option is specified. |
First Match |
Updates or deletes only the first matched row. |
Last Match |
Updates or deletes only the last matched row. |
Raise Error |
Fails the statement when more than one row is matched. |
Ignore |
Skips the operation when more than one row is matched. If exactly one row is matched, that row is processed. |
You can specify the option as a named value:
String sql = "UPDATE contacts SET update_source = 'Account' WHERE group_id = 'A' " + "USING OPTIONS (MultipleMatchAction = 'Last Match')"; statement.executeUpdate(sql);
Or as a single option value:
String sql = "DELETE FROM contacts WHERE group_id = 'A' USING OPTIONS ('Ignore')";
statement.executeUpdate(sql);
Executing Prepared Statements
Using a PreparedStatement can improve performance when you need to execute a SQL statement multiple times with different parameters. Unlike a Statement object, a PreparedStatement object is provided with a SQL statement when it is created, which can then be executed with different values each time. This special type of statement is derived from the more general Statement class.
Below are the steps outlining how to execute a prepared statement:
Creating and Executing a Prepared Statement
- Create a PreparedStatement
-
Use the
prepareStatementmethod of theConnectionclass to instantiate aPreparedStatement.For connection details, see Connecting with DriverManager or Connecting with DataSource.
- Set Parameters
- Declare parameters by calling the corresponding setter method of the
PreparedStatement. - NOTE: The parameter indices start at 1.
- Execute the PreparedStatement
- Use the generic
executeorexecuteUpdatemethod of thePreparedStatement. - Retrieve Results
- Call the
getResultSetmethod of thePreparedStatementto obtain the query results, which are returned as aResultSet. - Iterate Over the Result Set
- Use the
nextmethod of theResultSetto iterate through the results. To obtain column information, use theResultSetMetaDataclass. Instantiate aResultSetMetaDataobject by calling thegetMetaDatamethod of theResultSet.
SELECT
Use the PreparedStatement class's generic execute method or the executeQuery method to execute SQL statements that return data.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the retrieved data.
String sql = "SELECT * FROM contacts WHERE name = ?"; try { PreparedStatement ps = connection.prepareStatement(sql); ps.setString(1, "testName"); boolean ret = ps.execute(sql); if (ret) { ResultSet rs = ps.getResultSet(); LOGGER.info(rs.toString()); } } catch (SQLException e) { LOGGER.severe(e.toString()); }
INSERT
Use either the generic execute method or the executeUpdate method of the PreparedStatement class to execute an INSERT operation.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the ID of inserted data, exceptions raised during execution, and the data affected by the insertion.
String sql = "INSERT INTO emails (name, email_campaign_activities) VALUES (?, '{ \"format_type\": 5, \"from_name\": \"Your Brand\", \"from_email\": \"[email protected]\", \"reply_to_email\": \"[email protected]\", \"subject\": \"Hello from API\", \"html_content\": \"<!doctype html><html><body><h1>Hello!</h1><p>API test.</p></body></html>\" }')"; try { PreparedStatement ps = connection.prepareStatement(sql); ps.setString(1, "testName5"); ps.executeUpdate(); LOGGER.info(ps.getResultSet().toString()); } catch (SQLException e) { LOGGER.severe(e.toString()); }
id,errorcode,errormessage,processdata,haserrors
null,null,null,{"name":"testName5","email_campaign_activities":[{"format_type":5,"from_name":"Your Brand","from_email":"[email protected]","reply_to_email":"[email protected]","subject":"Hello from API","html_content":"<!doctype html><html><body><h1>Hello!</h1><p>API test.</p></body></html>"}]},false
UPDATE
Use either the generic execute method or the executeUpdate method of the PreparedStatement class to execute an UPDATE operation.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the ID of updated data, exceptions raised during execution, and the data affected by the update.
String sql = "UPDATE contacts SET email_address.address = '[email protected]', update_source = 'Account' WHERE name = ?"; try { PreparedStatement ps = connection.prepareStatement(sql); ps.setString(1, "testName"); ps.executeUpdate(); LOGGER.info(ps.getResultSet().toString()); } catch (SQLException e) { LOGGER.severe(e.toString()); }
id,errorcode,errormessage,processdata,haserrors
null,null,null,{"email_address":{"address":"[email protected]"},"update_source":"Account"},false
DELETE
Use either the generic execute method or the executeUpdate method of the PreparedStatement class to execute a DELETE operation.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the deleted data's ID, exceptions raised during execution, and details of the affected data.
String deleteSql = "DELETE FROM contacts WHERE name = ?"; try { PreparedStatement ps = connection.prepareStatement(deleteSql); ps.setString(1, "testName"); ps.executeUpdate(); LOGGER.info(ps.getResultSet().toString()); } catch (SQLException e) { e.printStackTrace(); }
id,errorcode,errormessage,processdata,haserrors null,null,null,null,false
Metadata Discovery
This section provides examples on how to retrieve table and column metadata using the getTables, getColumns, and getPrimaryKeys methods from the DatabaseMetaData interface. These are essential for discovering database structures.
Tables
The getTables method from the DatabaseMetaData interface can be used to retrieve a list of tables.
This method only retrieves tables that are not write-only.
To get a list of tables that includes write-only tables, query the table system.tables.
try { Connection connection = buildRestConnectionFromDriverManager(); ResultSet rs = connection.getMetaData().getTables(null, null, null, null); LOGGER.info("\r\n" + rs.toString()); } catch (SQLException e) { LOGGER.severe(e.getMessage()); }
TABLE_CAT,TABLE_SCHEM,TABLE_NAME,TABLE_TYPE,REMARKS null,null,account/emails,Table,null null,null,account/summary,Table,null null,null,account/summary/physical_address,Table,null null,null,account/user/privileges,Table,null null,null,activities,Table,null null,null,contact_custom_fields,Table,null null,null,contact_exports,Table,null null,null,contact_lists,Table,null null,null,contact_lists/list_id_xrefs,Table,null null,null,contact_tags,Table,null null,null,contacts,Table,null null,null,contacts/contact_id_xrefs,Table,null null,null,contacts/counts,Table,null null,null,contacts/sms_engagement_history,Table,null null,null,emails,Table,null null,null,emails/activities,Table,null ......
The getTables method returns the following metadata columns:
| Column Name | Data Type | Description |
|---|---|---|
| TABLE_CAT | String | The catalog that contains the table. |
| TABLE_SCHEM | String | The schema of the table. |
| TABLE_NAME | String | The name of the table. |
| TABLE_TYPE | String | The type of the table (e.g., TABLE or VIEW). |
| REMARKS | String | An optional description of the table. |
Columns
Use the getColumns method of the DatabaseMetaData interface to retrieve detailed information about database columns.
This method returns columns only for tables that are not write-only.
To get columns for write-only tables, query the table system.columns.
try { Connection connection = buildRestConnectionFromDriverManager(); ResultSet rs = connection.getMetaData().getColumns(null, null, "contacts", null); LOGGER.info(rs.toString()); } catch (SQLException e) { e.printStackTrace(); }
TABLE_CAT,TABLE_SCHEM,TABLE_NAME,COLUMN_NAME,DATA_TYPE,TYPE_NAME,COLUMN_SIZE,BUFFER_LENGTH,DECIMAL_DIGITS,NUM_PREC_RADIX,NULLABLE,REMARKS,COLUMN_DEF,SQL_DATA_TYPE,SQL_DATETIME_SUB,CHAR_OCTET_LENGTH,ORDINAL_POSITION null,null,contacts,anniversary,12,VARCHAR,10,null,0,0,null,null,null,12,null,null,null,null,null,null,DT_WSTR null,null,contacts,birthday_day,-5,BIGINT,null,null,0,0,null,null,null,-5,null,null,null,null,null,null,DT_I8 null,null,contacts,birthday_month,-5,BIGINT,null,null,0,0,null,null,null,-5,null,null,null,null,null,null,DT_I8 null,null,contacts,company_name,12,VARCHAR,50,null,0,0,null,null,null,12,null,null,null,null,null,null,DT_WSTR null,null,contacts,contact_id,12,VARCHAR,0,null,0,0,null,null,null,12,null,null,null,null,null,null,DT_WSTR null,null,contacts,contacts,12,VARCHAR,0,null,0,0,null,null,null,12,null,null,null,null,null,null,DT_WSTR null,null,contacts,contacts_count,-5,BIGINT,null,null,0,0,null,null,null,-5,null,null,null,null,null,null,DT_I8 null,null,contacts,create_source,12,VARCHAR,0,null,0,0,null,null,null,12,null,null,null,null,null,null,DT_WSTR null,null,contacts,created_at,93,TIMESTAMP,null,null,0,0,null,null,null,93,null,null,null,null,null,null,DT_DBTIMESTAMP ......
The getColumns method returns the following columns:
| Column Name | Data Type | Description |
|---|---|---|
| TABLE_CAT | String | The database name. |
| TABLE_SCHEM | String | The table schema. |
| TABLE_NAME | String | The table name. |
| COLUMN_NAME | String | The column name. |
| DATA_TYPE | Integer | The data type represented by a constant value from java.sql.Types. |
| TYPE_NAME | String | The data type name used by the driver. |
| COLUMN_SIZE | Integer | The length in characters of the column or the numeric precision. |
| BUFFER_LENGTH | Integer | The buffer length. |
| DECIMAL_DIGITS | Integer | The column scale or number of digits to the right of the decimal point. |
| NUM_PREC_RADIX | Integer | The radix, or base. |
| NULLABLE | Integer | Whether the column can contain null as defined by the following JDBC DatabaseMetaData constants: columnNoNulls (0) or columnNullable (1). |
| REMARKS | String | The comment or note associated with the object. |
| COLUMN_DEF | String | The default value for the column. |
| SQL_DATA_TYPE | Integer | Reserved by the specification. |
| SQL_DATETIME_SUB | Integer | Reserved by the specification. |
| CHAR_OCTET_LENGTH | Integer | The maximum length of binary and character-based columns. |
| ORDINAL_POSITION | Integer | The position of the column in the table, starting at 1. |
| IS_NULLABLE | String | Whether a null value is allowed: YES or NO. |
| SCOPE_CATALOG | String | The catalog of the table referenced by a reference attribute (null if DATA_TYPE is not REF). |
| SCOPE_SCHEMA | String | The schema of the table referenced by a reference attribute (null if DATA_TYPE is not REF). |
| SCOPE_TABLE | String | The name of the table referenced by a reference attribute (null if DATA_TYPE is not REF). |
| SOURCE_DATA_TYPE | Short | The source type of a distinct type or user-defined REF type (null if DATA_TYPE is neither DISTINCT nor a user-defined REF). |
| IS_AUTOINCREMENT | String | Whether the column value is assigned by Parquet in fixed increments. |
| IS_GENERATEDCOLUMN | String | Whether the column is generated: YES or NO. |
| DTS_TYPE | String | Object DTS attribute type. |
Primary Keys
The getPrimaryKeys method in the DatabaseMetaData interface is used to retrieve metadata about primary keys for a given table.
Note: Parquet is a columnar storage format and does not have a native concept of primary keys. Calling getPrimaryKeys against a Parquet table will always return an empty result set regardless of the table name supplied.
Connection Settings
| Connection Setting | Type | Default Value | Description |
|---|---|---|---|
| CacheExpirationTime | Integer | 30 | Defines the expiration time for cache. A value of 0 disables caching. |
| ConcurrentWritingThreads | Integer | 1 | The number of threads for executing operations in parallel. A value of 0 will disable multi threading. |
| DataSourceMode | String | "Directory" | Controls how logical tables are discovered from the Root Directory. Supported values are Directory and File. |
| FolderPath | String | "" | The root directory scanned for Parquet tables. Folder (Dataset) scans immediate subdirectories; File mode scans immediate parquet files. |
| ContinueOnErrors | Boolean | false | Determines if the program continues executing SQL statements after encountering an error. |
| LogFileSize | String | "10485760" | A string specifying the maximum size in bytes for a log file. |
| LogLevel | String | "INFO" | The logging level for the JDBC driver. |
| LogPath | String | "./jdbcLogs" | The directory where log files are stored. |
| OemKey | String | "" | The OEM license key. |
| ReadBatchSize | Integer | 1 | Not applicable for Parquet. The Parquet driver reads one row at a time and does not use this setting. |
| ResultPath | String | "" | The path where the execution result files are saved. |
| RetryOnIntermittentErrors | Boolean | true | The RetryOnIntermittentErrors parameter indicates whether to retry the connection when it might occasionally fail due to temporary issues. |
| SaveResult | Boolean | false | The SaveResult parameter indicates whether to save the execution results to a file. |
| ServiceName | String | "" | The ServiceName refers to the name of the service selected by the user. |
| WriteBatchSize | Integer | 5000 | In Folder (Dataset), WriteBatchSize can split one INSERT across multiple parquet files. In File mode, the single backing parquet file is still preserved and rewritten in place. |