Copper
Building the JDBC URL
After installing the license, open the connection management page by running java -jar kingswaysoft.jdbc.jar. Enter the required details to generate the JDBC connection URL. Click Test Connection to test the generated URL, or Copy to Clipboard to copy the connection string for use in your application.
Note: If the license is not installed, you can still use the connection manager to generate a JDBC URL; however, the 'Test Connection' feature will be disabled.
General Page
The General page of the Copper Connection Manager allows you to specify the general settings of the connection:
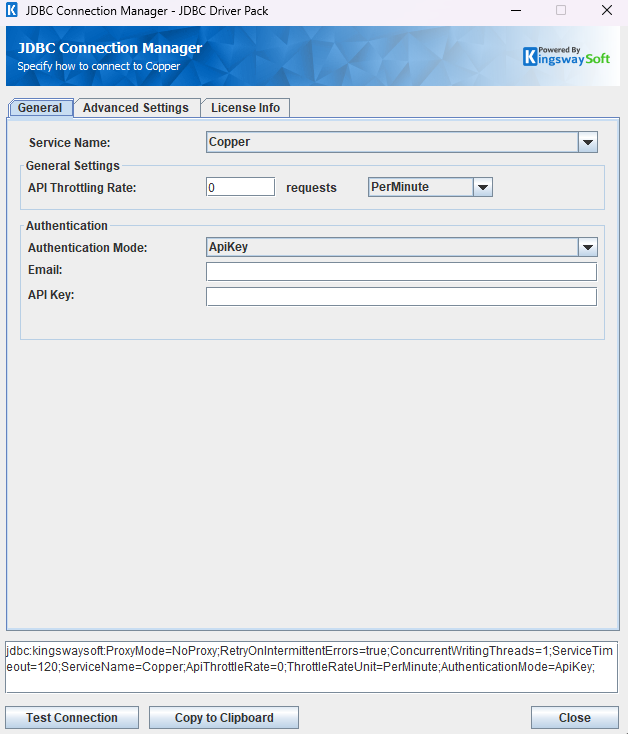
General Settings
- API Throttling Rate
-
The API Throttling Rate will limit the number of requests that can be sent per the selected unit of time. Set this value to 0 to disable API throttling.
Authentication Methods for Copper
API Key
-
A user's Copper account email address to identify and authenticate API requests.
- API Key
-
If you have an API Key that you would like to use, enter it in the authentication field.
OAuth
A saved token file and token password can be used to establish a connection. If you wish to generate a new token file, click Generate Token File to go through the token generation process, save the token file locally, and use the specified token password to connect.
- Generate Token File
-
This button completes the OAuth authentication process to generate a new token.
- Client ID: The Client ID option allows you to specify the unique ID which identifies the application making the request.
- Client Secret: The Client Secret option allows you to specify the client secret belonging to your app.
- Redirect URL: The Redirect URL option allows you to specify the Redirect URL to complete the authentication process.
- Scope: Copper requires the scope to be specified as
developer/v1/all
- Path To Token File
-
The path to the token file on the file system.
- Token File Password
-
The Password for the token file.
Advanced Settings Page
The Advanced Settings page allows you to specify advanced settings for the connection.
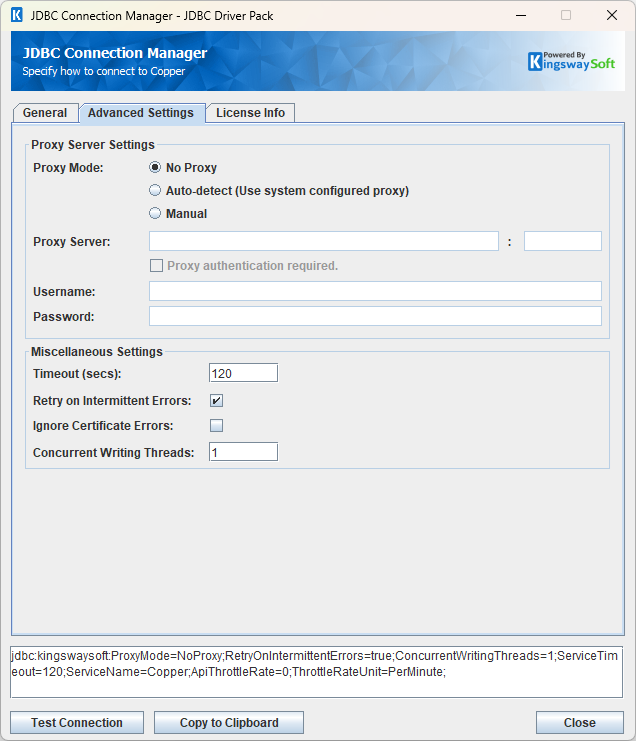
Proxy Server Settings
- Proxy Mode
-
The Proxy Mode option allows you to specify how you want to configure the proxy server setting. There are three options available.
- No Proxy
- Auto-detect (Use system configured proxy)
- Manual
- Proxy Server
-
Using the Proxy Server option allows you to specify the name of the proxy server for the connection.
- Port
-
The Port option allows you to specify the port number of the proxy server for the connection.
- Username (Proxy Server Authentication)
-
The Username option (under Proxy Server Authentication) allows you to specify the proxy user account.
- Password (Proxy Server Authentication)
-
The Password option (under Proxy Server Authentication) allows you to specify the proxy user's password.
Miscellaneous Settings
- Timeout (secs)
-
The Timeout (secs) option allows you to specify a timeout value in seconds for the connection. The default value is 120 seconds. Specify 0 for infinite timeout.
- Retry on Intermittent Errors
-
The retry on intermittent errors determines if requests will be retried when there is an error. If this option is checked requests will be retried up to 3 times.
- Ignore Certificate Errors
-
This option can be used to ignore those SSL certificate errors when connecting to the target server.
Warning: Enabling the "Ignore Certificate Errors" option is generally NOT recommended, particularly for production instances. Unless there is a strong reason to believe the connection is secure - such as the network communication is only happening in an internal infrastructure, this option should be unchecked for the best security.
Note: When this option is enabled, it applies to all HTTP-based SSL connections in the same job process.
- Concurrent Writing Threads
-
This option can be used to set the number of threads to be used during write operations. This can improve performance during large-volume write operations.
Using the JDBC Driver
This section provides examples that use JDBC classes such as Connection, Statement, and ResultSet to manage interactions with Copper data. It covers regular statements and prepared statements for complex or frequently executed queries.
Executing Statements
After you have connected from your code, you can execute SQL statements using the Statement class. For connection details, see Connecting with DriverManager or Connecting with DataSource. For parameterized statements, see Executing Prepared Statements.
SELECT
Use the Statement class's generic execute method or the executeQuery method to execute SQL statements that return data. To retrieve the results of a query, call the getResultSet method of the Statement.
String sql = "SELECT * FROM projects WHERE id = 1654453"; try { ResultSet resultSet = statement.executeQuery(sql); LOGGER.info(resultSet.toString()); } catch (SQLException e) { LOGGER.severe(e.toString()); }
INSERT
Use either the generic execute method or the executeUpdate method of the Statement class to execute an INSERT operation.
User can pass driver-specific write options by appending a USING OPTIONS (...) clause at the end of the INSERT statement, and it will override the WriteBatchSize defined in the properties.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the inserted data's ID, exceptions raised during execution, and details of the affected data.
String sql = "INSERT INTO projects (name) VALUES ('ProjectName')"; try { statement.executeUpdate(sql); LOGGER.info(statement.getResultSet().toString()); } catch (SQLException e) { LOGGER.severe(e.toString()); }
id,errorcode,errormessage,processdata,haserrors
1654639,null,null,{"name":"ProjectName"},false
UPDATE
Use either the generic execute method or the executeUpdate method of the Statement class to execute an UPDATE operation.
User can pass driver-specific write options by appending a USING OPTIONS (...) clause at the end of the UPDATE statement, and it will override the WriteBatchSize defined in the properties.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the updated data's ID, exceptions raised during execution, and details of the affected data.
String sql = "UPDATE projects SET name = 'ProjectUpdateName' WHERE id = 1654639"; try { statement.executeUpdate(sql); LOGGER.info(statement.getResultSet().toString()); } catch (SQLException e) { LOGGER.severe(e.toString()); }
id,errorcode,errormessage,processdata,haserrors
1654639,null,null,{"name":"ProjectUpdateName"},false
DELETE
Use either the generic execute method or the executeUpdate method of the Statement class to execute a DELETE operation.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the deleted data's ID, exceptions raised during execution, and details of the affected data.
String sql = "DELETE FROM projects WHERE id = 1654639"; try { statement.executeUpdate(sql); LOGGER.info(statement.getResultSet().toString()); } catch (SQLException e) { LOGGER.severe(e.toString()); }
id,errorcode,errormessage,processdata,haserrors 1654639,null,null,null,false
UPSERT
Using the UPSERT operation, you can either insert or update an existing record in one call.
Not all tables support the upsert operation. Query the system.tables table to identify which tables support UPSERT operations.
If the key isn't matched, then a new object record is created.
If the specified key is matched, the action taken will depend on if there were multiple matches or not.
- If the key is matched once, the existing object record is updated.
- If the key is matched multiple times, an error is generated and the object record is not inserted or updated.
The Upsert SQL statement must end with ON DUPLICATE KEY UPDATE UPSERTFIELDS = key, where key refers to the field specified by the user as the upsert key.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the ID of upserted data, exceptions raised during execution, and the data affected by the upsert.
String sql = "UPSERT INTO leads (name, email.email, email.category) VALUES ('My Lead', '[email protected]', 'work') ON DUPLICATE KEY UPDATE UPSERTFIELDS = (name)"; try { statement.executeUpdate(sql); LOGGER.info(statement.getResultSet().toString()); } catch (SQLException e) { LOGGER.severe(e.toString()); }
id,errorcode,errormessage,processdata,haserrors
8982702,null,null,{"match":{"field_name":"name","field_value":"My Lead"},"properties":{"name":"My Lead","email":{"email":"[email protected]","category":"work"}}},false
Executing Prepared Statements
Using a PreparedStatement can improve performance when you need to execute a SQL statement multiple times with different parameters. Unlike a Statement object, a PreparedStatement object is provided with a SQL statement when it is created, which can then be executed with different values each time. This special type of statement is derived from the more general Statement class.
Below are the steps outlining how to execute a prepared statement:
Creating and Executing a Prepared Statement
- Create a PreparedStatement
-
Use the
prepareStatementmethod of theConnectionclass to instantiate aPreparedStatement.For connection details, see Connecting with DriverManager or Connecting with DataSource.
- Set Parameters
- Declare parameters by calling the corresponding setter method of the
PreparedStatement. - NOTE: The parameter indices start at 1.
- Execute the PreparedStatement
- Use the generic
executeorexecuteUpdatemethod of thePreparedStatement. - Retrieve Results
- Call the
getResultSetmethod of thePreparedStatementto obtain the query results, which are returned as aResultSet. - Iterate Over the Result Set
- Use the
nextmethod of theResultSetto iterate through the results. To obtain column information, use theResultSetMetaDataclass. Instantiate aResultSetMetaDataobject by calling thegetMetaDatamethod of theResultSet.
SELECT
Use the PreparedStatement class's generic execute method or the executeQuery method to execute SQL statements that return data.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the retrieved data.
String sql = "SELECT * FROM projects WHERE id = ?"; try { PreparedStatement ps = connection.prepareStatement(sql); ps.setInt(1, 1654453); ps.execute(query); while (ps.getResultSet().next()) { for (int i = 1; i <= ps.getResultSet().getMetaData().getColumnCount(); i++) { LOGGER.info(ps.getResultSet().getMetaData().getColumnLabel(i) + "=" + ps.getResultSet().getString(i)); } } } catch (SQLException e) { LOGGER.error(e); }
INSERT
Use either the generic execute method or the executeUpdate method of the PreparedStatement class to execute an INSERT operation.
User can pass driver-specific write options by appending a USING OPTIONS (...) clause at the end of the INSERT statement, and it will override the WriteBatchSize defined in the properties.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the ID of inserted data, exceptions raised during execution, and the data affected by the insertion.
String sql = "INSERT INTO projects (name) VALUES (?)"; try { PreparedStatement ps = connection.prepareStatement(sql); ps.setString(1, "ProjectName"); ps.executeUpdate(); LOGGER.info(ps.getResultSet().toString()); } catch (SQLException e) { LOGGER.error(e); }
d,errorcode,errormessage,processdata,haserrors
1654639,null,null,{"name":"ProjectName"},false
UPDATE
Use either the generic execute method or the executeUpdate method of the PreparedStatement class to execute an UPDATE operation.
User can pass driver-specific write options by appending a USING OPTIONS (...) clause at the end of the UPDATE statement, and it will override the WriteBatchSize defined in the properties.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the ID of updated data, exceptions raised during execution, and the data affected by the update.
String sql = "UPDATE projects SET name = ? WHERE id = ?"; try { PreparedStatement ps = connection.prepareStatement(sql); ps.setString(1, "ProjectUpdateName"); ps.setInt(2, 1654639); ps.executeUpdate(); LOGGER.info(ps.getResultSet().toString()); } catch (SQLException e) { LOGGER.error(e); }
id,errorcode,errormessage,processdata,haserrors
1654639,null,null,{"name":"ProjectUpdateName"},false
DELETE
Use either the generic execute method or the executeUpdate method of the PreparedStatement class to execute a DELETE operation.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the deleted data's ID, exceptions raised during execution, and details of the affected data.
String sql = "DELETE FROM projects WHERE id = ?"; try { PreparedStatement ps = connection.prepareStatement(sql); ps.setInt(1, 1654639); ps.executeUpdate(); LOGGER.info(ps.getResultSet().toString()); } catch (SQLException e) { LOGGER.error(e); }
id,errorcode,errormessage,processdata,haserrors 1654639,null,null,null,false
UPSERT
Using the UPSERT operation, you can either insert or update an existing record in one call.
Not all tables support the upsert operation. Query the system.tables table to identify which tables support UPSERT operations.
If the key isn't matched, then a new object record is created.
If the specified key is matched, the action taken will depend on if there were multiple matches or not.
- If the key is matched once, the existing object record is updated.
- If the key is matched multiple times, an error is generated and the object record is not inserted or updated.
The Upsert SQL statement must end with ON DUPLICATE KEY UPDATE UPSERTFIELDS = key, where key refers to the field specified by the user as the upsert key.
The results of SQL queries are saved in a ResultSet. You can retrieve the ResultSet after execution to view the ID of upserted data, exceptions raised during execution, and the data affected by the upsert.
String sql = "UPSERT INTO leads (name, email.email, email.category) VALUES (?, ?, ?) ON DUPLICATE KEY UPDATE UPSERTFIELDS = (name)"; try { PreparedStatement ps = connection.prepareStatement(sql); ps.setString(1, "My Lead"); ps.setString(2, "[email protected]"); ps.setString(3, "work"); ps.executeUpdate(); LOGGER.info(ps.getResultSet().toString()); } catch (SQLException e) { LOGGER.error(e); }
id,errorcode,errormessage,processdata,haserrors
8982702,null,null,{"match":{"field_name":"name","field_value":"My Lead"},"properties":{"name":"My Lead","email":{"email":"[email protected]","category":"work"}}},false
Metadata Discovery
This section provides examples on how to retrieve table and column metadata using the getTables, getColumns, and getPrimaryKeys methods from the DatabaseMetaData interface. These are essential for discovering database structures.
Tables
The getTables method from the DatabaseMetaData interface can be used to retrieve a list of tables.
This method only retrieves tables that are not write-only.
To get a list of tables that includes write-only tables, query the table system.tables.
try { Connection connection = buildRestConnectionFromDriverManager(); ResultSet rs = connection.getMetaData().getTables(null, null, null, null); LOGGER.info("\r\n" + rs.toString()); } catch (SQLException e) { LOGGER.severe(e.getMessage()); }
TABLE_CAT,TABLE_SCHEM,TABLE_NAME,TABLE_TYPE,REMARKS null,null,account,Table,null null,null,activities,Table,null null,null,activity_types,Table,null null,null,companies,Table,null null,null,companies/activities,Table,null null,null,contact_types,Table,null null,null,custom_activity_types,Table,null null,null,custom_field_definitions,Table,null null,null,customer_sources,Table,null null,null,files,Table,null ......
The getTables method returns the following metadata columns:
| Column Name | Data Type | Description |
|---|---|---|
| TABLE_CAT | String | The catalog that contains the table. |
| TABLE_SCHEM | String | The schema of the table. |
| TABLE_NAME | String | The name of the table. |
| TABLE_TYPE | String | The type of the table (e.g., TABLE or VIEW). |
| REMARKS | String | An optional description of the table. |
Columns
Use the getColumns method of the DatabaseMetaData interface to retrieve detailed information about database columns. To narrow the results to a specific table, specify the table name using the parameter table_name.
This method returns columns only for tables that are not write-only.
To get columns for write-only tables, query the table system.columns.
try { Connection connection = buildRestConnectionFromDriverManager(); ResultSet rs = connection.getMetaData().getColumns(null, null, "projects", null); LOGGER.info(rs.toString()); } catch (SQLException e) { e.printStackTrace(); }
TABLE_CAT,TABLE_SCHEM,TABLE_NAME,COLUMN_NAME,DATA_TYPE,TYPE_NAME,COLUMN_SIZE,BUFFER_LENGTH,DECIMAL_DIGITS,NUM_PREC_RADIX,NULLABLE,REMARKS,COLUMN_DEF,SQL_DATA_TYPE,SQL_DATETIME_SUB,CHAR_OCTET_LENGTH,ORDINAL_POSITION,IS_NULLABLE,IS_AUTOINCREMENT,IS_GENERATEDCOLUMN,DTS_TYPE null,null,projects,assignee_id,-5,BIGINT,null,null,0,0,null,null,null,-5,null,null,null,null,null,null,DT_I8 null,null,projects,date_created,93,TIMESTAMP,null,null,0,0,null,null,null,93,null,null,null,null,null,null,DT_DBTIMESTAMP null,null,projects,date_modified,93,TIMESTAMP,null,null,0,0,null,null,null,93,null,null,null,null,null,null,DT_DBTIMESTAMP null,null,projects,details,12,VARCHAR,null,null,0,0,null,null,null,12,null,null,null,null,null,null,DT_WSTR null,null,projects,id,-5,BIGINT,null,null,0,0,null,null,null,-5,null,null,null,null,null,null,DT_I8 null,null,projects,name,12,VARCHAR,null,null,0,0,null,null,null,12,null,null,null,null,null,null,DT_WSTR null,null,projects,related_resource.id,-5,BIGINT,null,null,0,0,null,null,null,-5,null,null,null,null,null,null,DT_I8 null,null,projects,related_resource.type,12,VARCHAR,null,null,0,0,null,null,null,12,null,null,null,null,null,null,DT_WSTR null,null,projects,status,12,VARCHAR,null,null,0,0,null,null,null,12,null,null,null,null,null,null,DT_WSTR null,null,projects,tags,12,VARCHAR,null,null,0,0,null,null,null,12,null,null,null,null,null,null,DT_WSTR ......
The getColumns method returns the following columns:
| Column Name | Data Type | Description |
|---|---|---|
| TABLE_CAT | String | The database name. |
| TABLE_SCHEM | String | The table schema. |
| TABLE_NAME | String | The table name. |
| COLUMN_NAME | String | The column name. |
| DATA_TYPE | Integer | The data type represented by a constant value from java.sql.Types. |
| TYPE_NAME | String | The data type name used by the driver. |
| COLUMN_SIZE | Integer | The length in characters of the column or the numeric precision. |
| BUFFER_LENGTH | Integer | The buffer length. |
| DECIMAL_DIGITS | Integer | The column scale or number of digits to the right of the decimal point. |
| NUM_PREC_RADIX | Integer | The radix, or base. |
| NULLABLE | Integer | Whether the column can contain null as defined by the following JDBC DatabaseMetaData constants: columnNoNulls (0) or columnNullable (1). |
| REMARKS | String | The comment or note associated with the object. |
| COLUMN_DEF | String | The default value for the column. |
| SQL_DATA_TYPE | Integer | Reserved by the specification. |
| SQL_DATETIME_SUB | Integer | Reserved by the specification. |
| CHAR_OCTET_LENGTH | Integer | The maximum length of binary and character-based columns. |
| ORDINAL_POSITION | Integer | The position of the column in the table, starting at 1. |
| IS_NULLABLE | String | Whether a null value is allowed: YES or NO. |
| IS_AUTOINCREMENT | String | Whether the column value is assigned by Copper in fixed increments. |
| IS_GENERATEDCOLUMN | String | Whether the column is generated: YES or NO. |
| DTS_TYPE | String | Object DTS attribute type. |
Primary Keys
The getPrimaryKeys method in the DatabaseMetaData interface is used to retrieve metadata about primary keys for a given table in Copper.
try { Connection connection = buildRestConnectionFromDriverManager(); ResultSet resultSet = connection.getMetaData().getPrimaryKeys(null, null, "projects"); LOGGER.info("\r\n" + resultSet.toString()); } catch (SQLException e) { LOGGER.severe(e.getMessage()); }
TABLE_NAME,PRIMARY_COLUMN_NAME projects,id
The getPrimaryKeys method returns the following columns:
| Column Name | Data Type | Description |
|---|---|---|
| TABLE_NAME | String | The name of the table that contains the primary key. |
| PRIMARY_COLUMN_NAME | String | The name of the column that serves as the primary key for the table. |
Connection Settings
| Connection Setting | Type | Default Value | Description |
|---|---|---|---|
| ApiKey | String | "" | A Copper authentication token used to call the REST API |
| ApiThrottleRate | Integer | 0 | The maximum number of API requests a client can make to the server within a specified time period, as set by ThrottleRateUnit. |
| CacheExpirationTime | Integer | 30 | Defines the expiration time for cache. A value of 0 disables caching. |
| ConcurrentWritingThreads | Integer | 1 | The number of threads for executing operations in parallel. A value of 0 will disable multi threading. |
| ConnectionTimeout | Integer | 30 | ConnectionTimeout is the maximum amount of time the program will wait to set up a connection to the Copper API. |
| IgnoreCertificateErrors | Boolean | false | Specifies whether to verify the certificate when connecting to Copper. If no certificate verification is required, you can set this value to 'true'. |
| ContinueOnErrors | Boolean | false | Determines if the program continues executing SQL statements after encountering an error. |
| LogFileSize | String | "10485760" | A string specifying the maximum size in bytes for a log file. |
| LogLevel | String | "INFO" | The logging level for the JDBC driver. |
| LogPath | String | "./jdbcLogs" | The directory where log files are stored. |
| OemKey | String | "" | The OEM license key. |
| PathToTokenFile | String | "" | The PathToTokenFile specifies the file path where the token for connecting to Basecamp is located. |
| ProxyMode | String | "NoProxy" | This setting configures the proxy. Allowed values are "NoProxy", "AutoDetect" and "Manual". |
| ProxyPassword | String | "" | The password to be used to authenticate to the proxy. |
| ProxyServer | String | "" | The host of the proxy server. |
| ProxyServerPort | Integer | 0 | The port of the proxy server. |
| ProxyUsername | String | "" | The username to be used to authenticate to the proxy. |
| ReadBatchSize | Integer | 100 | ReadBatchSize is used to set how many records can be read from Copper in a single call. Copper has a maximum ReadBatchSize of 100. |
| ResultPath | String | "" | The path where the execution result files are saved. |
| RetryOnIntermittentErrors | Boolean | true | The RetryOnIntermittentErrors parameter indicates whether to retry the connection when it might occasionally fail due to temporary issues. |
| SaveResult | Boolean | false | The SaveResult parameter indicates whether to save the execution results to a file. |
| ServiceName | String | "Copper" | The ServiceName refers to the name of the service API selected by the user. |
| ServiceTimeout | Integer | 120 | The ServiceTimeout is the timeout to receive the full response from Copper API. |
| Suppress404NotFoundError | Boolean | true | When set to true, if a query results in an HTTP 404 error, a result set will still be created. When set to false, an error is logged instead and no result set is created. |
| ThrottleRateUnit | String | "PerMinute" | The unit of time for limiting API requests to avoid being throttled. Valid values include, "PerSecond", "PerMinute" and "PerHour". |
| TokenPassword | String | "" | The password used to read the token file. |
| UserEmail | String | "" | Used for API Key authentication. The email address of the Copper user associated with the API Key. |
| WriteBatchSize | Integer | 1 | WriteBatchSize is used to set how many records can be written to Copper in a single call. |