KingswaySoft provides Email Source component in our SSIS Productivity Pack which can be used to read email messages from your mailboxes. And this component supports the following three protocols, it can be used to read emails from various email systems, including Microsoft Office 365, Exchange Server, Gmail, and almost all other major email services.
- Exchange Web Services (EWS)
- IMAP
- POP3
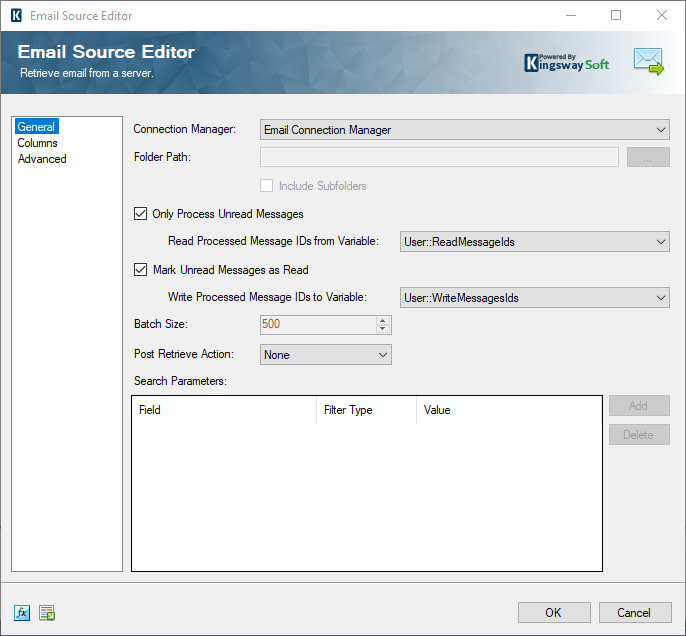
A common business case would be having an automated process in which you read those newly arrived messages since the last job run in order for facilitate an incremental read from your email system. Now, in order to get the unread emails, its fairly easy in EWS and IMAP, as they support reading “Read” flags on messages. And in our Email Source component there is an option called “Only Process Unread Messages” which, when enabled, would only pick up those emails that are unread. And similarly, the option “Mark Unread Messages as Read” would write a “Read” flag to the email messages after the message has been read and processed. However, when using POP3 protocol, this may not be a direct approach, as POP3 doesn’t support reading or writing the “Read” flags on messages. And therefore, while working with POP3 protocol, it requires a different strategy to be used. In our KingswaySoft Email Source component, we provide the options to make this easier. This blog post discusses the design which you would implement to perform the above logic while working with POP3 protocol. The below components would be used in this example, and all of them are available as a part of our SSIS Productivity pack.
- Email Source component
- Premium Derived Column component
- Premium Flat File Destination component
- Premium Aggregate component
- Data Spawner
Design Flow
Before we begin, please refer to the image below. As you can see there is an option called “Read Processed Message IDs from Variable” which has a variable “ReadMessageIds” that we can set. And this variable would contain the message Ids for existing emails, and the component would read the emails by excluding these IDs. Then there is the “Write Processed Message IDs to Variable” which has the variable “WriteMessageIds” set, which will contain all the read message Ids, including those newly ones, which can be used in the next run.
Now, let’s get into the design. The general logic would be to have two Data Flow Tasks – out of which the first Data flow Task (DFT1) would read a set of comma separated list of messageIds from a text file, and save it to the variable “ReadMessageIds”. And in the second Data flow Task – DFT2, we will have our Email Source component that uses the “ReadMessageIds” to read only the unread messages, that is, everything except the list of message Ids in the variable. Please note that in the first run, the variable would be empty, and hence all email messages would be read. And after reading the email messages, the message Ids for those read messages would be saved as comma separated values to the variable “WriteMessageIds” which will then be saved back to the text file. And this text file would be used in the next run and so on. The complete process flow would look as shown below.
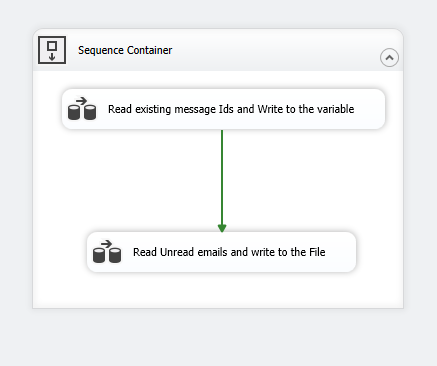
Let’s see how the data flow tasks can be designed.
DFT1 – Read existing message Ids and Write to the variable
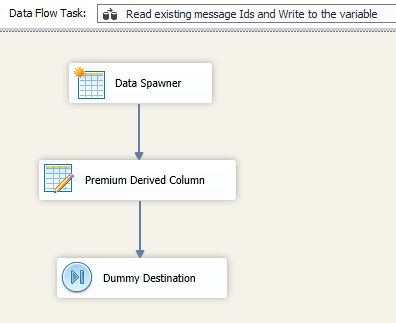
In DFT1, you would have a data spawner component to begin with, which is used as a dummy Source component. This is required, as we need to use a Premium Derived Column component next and since it’s a transformation component, it needs a Source input. In the Premium Derived Column component, we provide the below function, that would read from the text file (the comma separated Message Ids) and write to the text file.
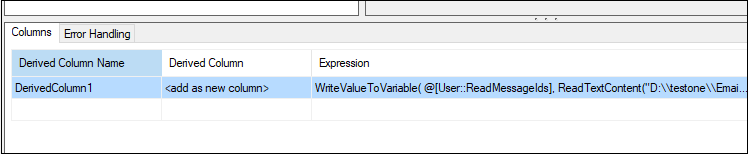
WriteValueToVariable( @[User::ReadMessageIds], ReadTextContent("D:\\testone\\Email Test\\New.csv" ) )
And then we provide a Dummy Destination component to serve as a Destination for the Premium Derived Column transformation component.
DFT2 – Read Unread emails and write to the File
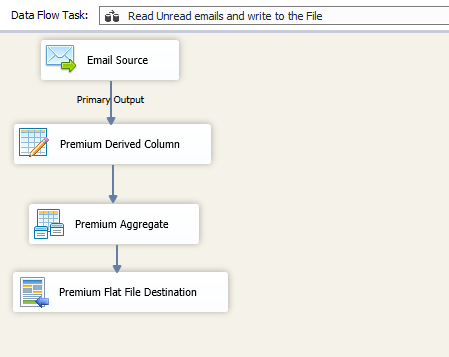
In DFT2, we use our Email Source component and configure it as we had seen in the initial screenshot. And then, by using the Premium Derived Column component after that, write the output variable “WriteMessageIds” to a Derived column. Further below, we use our Premium aggregate component in order to group by the records.
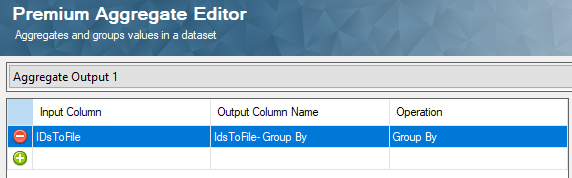
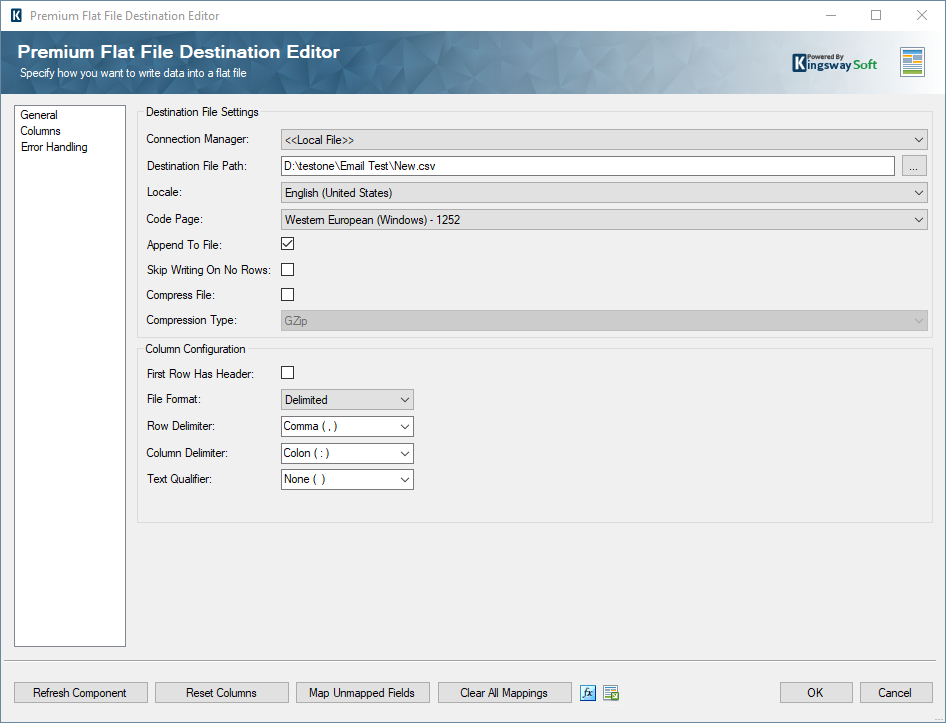
And finally, we use a Premium Flat File Destination component to write the newly read message Ids to the text file, by mapping that aggregated column with the message Id to the field in the text file.
Conclusion
Now, you could use this design and run the automated process (job) and you would see that in the first run, you get all the message Ids from the mailbox, and then from the next run onwards, it would only read the newly arrived messaged, and “flags” them as read with respect to the design, so that the next run picks up only the next newly arrived email messages. We have a sample package attached along with this (Link here) which you can download, and open to see the whole design process, and which can also be used to design your own data flow.