Using the Premium Lookup Component
The Premium Lookup Component is an SSIS data flow pipeline component that can be used to search for rows in a lookup table based on fields from rows in a primary input. It offers a flexible way to perform lookup against any data sources. The component supports both exact match and approximate match (often referred to as fuzzy) for lookup purposes.
Each primary row is compared to the lookup table (or source) based on the specified filters and determined to either be an unmatched or matched row before they are directed to the applicable output. In the case of a matched row, a single input row may produce multiple matched rows if there were several rows in the lookup table that were exact or approximate matches.
This component requires 2 inputs:
| Input Name | Description |
| Lookup Table Input | The lookup table input contains the data that the component will search through in order to find matching records. |
| Primary Input | The primary input rows are used to search the lookup table for a matching record. |
The component has 2 outputs:
| Output Name | Row Type | Description |
| Unmatched Rows | Primary Input Row | Primary input rows that did not match any rows in the lookup table. |
| Matched Rows | Primary Input Rows, Lookup Table Rows and Calculated Columns | When a primary input row matches a row in the lookup table a matched row is produced. A matched row has columns from the primary input, the lookup table, and calculated columns that contain statistics about the match. If a primary row matches multiple rows in the lookup table a matched row will be directed for each matching row. |
The component includes the following four pages to configure how you want to search for data.
- General
- Comparison Settings
- Columns
- Error Handling
General Page
The General page of the Premium Lookup Component allows you to specify the general settings of the component.
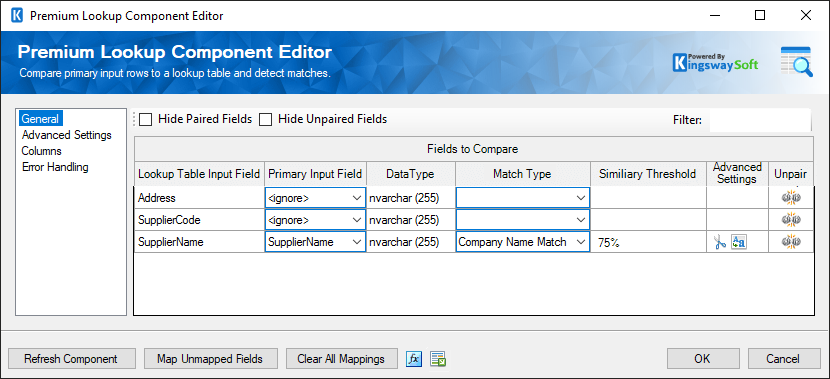
- Fields to Compare grid
-
The Fields To Compare grid will display all the available fields from the lookup table. Each of these fields can be paired with a field in the primary input. For every paired field a lookup type must be chosen.
- Lookup Type Column
-
The lookup type for paired fields can be set to either Exact Match, the generic Fuzzy Match, or a more specific match type. Exact match columns must be matched exactly to be considered matches. Fuzzy Match columns must meet a similarity threshold. If you select Fuzzy Match as the lookup type the similarity threshold will be enabled. Only string types such as VARCHAR, NVARCHAR, NTEXT, and TEXT can be used with a fuzzy match filter, a warning will be shown if any other type is selected. The available match types are:
- Exact Match: Fields must be exactly the same to be considered a match. The Similarity Threshold slider is disabled because matches must always have a similarity of 100%.
-
Fuzzy Match: Strings are considered a match if their similarity is above the specified similarity threshold.
- With Token Delimiters - If token delimiters are specified input strings are separated into parts based on the delimiters before comparison, and each of the resulting tokens in the input row is compared with the lookup row. This can result in more accurate results for data with delimiters but will be more performance intensive.
- No Token Delimiters - If no token delimiters are specified the entire input string is compared to the entire lookup string.
- First Name Match: Strings are treated as first names, and common nicknames are treated as the same name. For example, Bill and William would be an exact match.
- Phone Number Match: Strings are parsed to attempt to identify a 10-digit phone number which is used for comparison, ignoring any other characters.
- Street Address Match: Strings are treated as street addresses, and common street name prefixes and directions are treated as equivalent. For example N. and North, or Avenue and Av. would be treated as exact matches.
- US Zip Code Match: Strings are parsed to attempt to identify a 5 or 9-digit zip code which is used for comparison, ignoring other characters.
- Company Name: Strings are treated as company names, and common company suffixes such as INC, CORP, and LLC are ignored when comparing.
- Country Match (since v7.1): Strings are treated as country names, and country codes are matched with English short country names. For example, Canada and CA would be an exact match.
- US State Match (since v7.1): Strings are treated as states, and codes are matched with the subdivision names. For example, New York and NY would be an exact match.
- Similarity Threshold Column
-
When a lookup type other than Exact Match is selected for paired fields the similarity threshold slider will be enabled. The similarity threshold is a value between 1% and 100% that determines how similar the values need to be in order to be considered matches. A value of 1% would be not similar at all and a value of 100% would be an exact match.
- Advanced Comparison Settings Column
-
The advanced comparison properties display the comparison settings that can be specified at the column level. If you edit this column and click on the button a dialog will launch that allows you to edit the comparison settings.
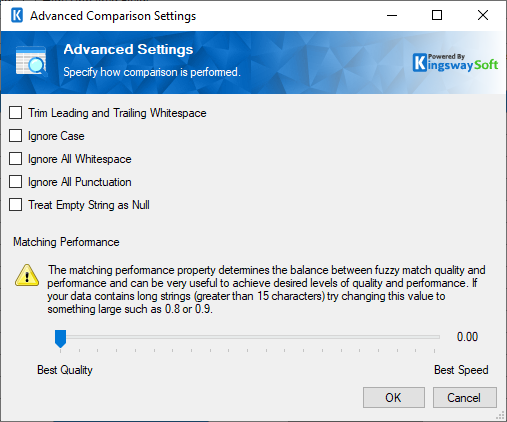
- Trim Leading and Trailing Whitespace
-
Selecting the Trim Leading and Trailing Whitespace option will remove all whitespace at the beginning and end of the primary field and the lookup field when comparing.
- Ignore Case
-
Selecting the Ignore Case option will ignore the case of the primary field and the lookup field when comparing.
- Ignore All Whitespace
-
Selecting the Ignore All Whitespace option will remove all whitespace from the primary field and the lookup field when comparing.
- Ignore All Punctuation
-
Selecting the Ignore All Punctuation option will remove all punctuation from the primary field and the lookup field when comparing.
- Treat Empty String as Null (since v6.0)
-
Enabling this option allows you to specify whether to treat the empty string as NULLs when performing lookup in Premium Lookup Component.
- Token Delimiters (since v8.0)
-
Specify the delimiters that the transformation uses to tokenize column values.
- Matching Performance
-
The Matching Performance slider will determine the balance between the quality and speed of your results. Increasing this value will result in faster performance but fewer matches found in the lookup table. Default values are set for each of the fuzzy match types, but this can be adjusted if performance is found to be too slow, or if accuracy is too low.
- Hide Unpaired Fields
-
When the Hide Unpaired Fields checkbox is checked only paired reference table columns will be shown.
- Hide Paired Fields
-
When the Hide Paired Fields checkbox is checked only unpaired reference table columns will be shown.
- Refresh Component Button
-
Clicking the Refresh Component button will reload input columns from the reference table and primary inputs.
- Pair Unpaired Fields Button
-
Clicking the Pair Unpaired Fields button will attempt to pair all the reference table input fields to primary input fields with matching names.
- Clear All Pairings Button
-
Clicking the Clear All Pairings button will clear all pairings between the reference table and primary fields.
Advanced Settings Page
The Advanced Settings page of the Premium Lookup Component allows you to specify the settings that will be used when comparing fields.
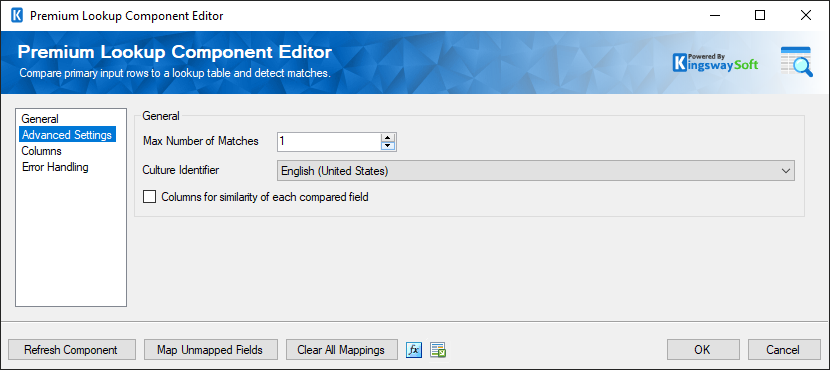
- General
-
- Max Number of Matches
-
The Max Number of Matches property determines the maximum number of matches that will be found for each primary input row. If the number of matches is higher than this number the best matches will be displayed.
- Culture Identifier
-
The Culture Identifier allows better string comparison by taking cultural-specific string comparison rules into account.
- Columns for Similarity of Each Compared Field
-
When the Columns for Similarity of Each Compared Field is checked a column will be added to matched output for each paired field. The value in each field will be the similarity of those fields for the compared row. The name of each column will be the name of the lookup field preceded by the _similarity_ prefix.
Columns
The Columns page of the Premium Lookup component allows you to specify which columns will be part of the output. Columns can be toggled for the Matched Rows output and the Unmatched Rows output. Available columns are all the input columns, and 4 calculated columns in the Matched Rows output.
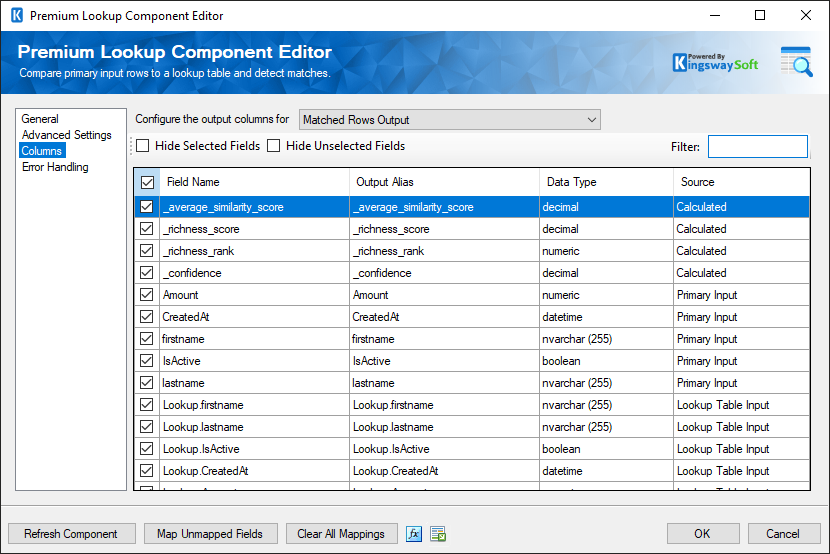
- The Columns Grid consists of the below fields.
-
- Field Name: This would show the output fields.
- Output Alias(since v22.1): This field shows the Output Alias name, which is editable
- Data Type: The data type of the field.
- Source: The source of the field.
- Average Similarity Score (Calculated Column)
-
The Average Similarity Score column displays the average similarity score of all compared fields. Fields that are an exact match have a similarity of 100% and fields that are a fuzzy match will have a score of less than 100%.
- Richness Score (Calculated Column)
-
The Richness Score column displays the richness of the row from the lookup table. Richness is calculated based on the number of fields that are null or empty. A row with data in every field would have a richness of 1.
- Richness Rank (Calculated Column)
-
The Richness Rank column displays the rank of the row based on its richness relative to the other matches found. For example, if 5 matches are found the match with the highest richness will be ranked 1 and the match with the lowest richness will be ranked 5.
- Confidence Score (Calculated Column)
-
The Confidence column displays the confidence score for the match, which is a representation of how probable it is that this is the correct match. If there is a single match, the confidence will be the same as the average similarity for the row. The highest confidence scores will come from a single match with very high similarity. If there are multiple matches, the matches will each be assigned a weight based on their similarity relative to the similarity of other matches and will be assigned some fraction of the total confidence. The more matches that are found the lower the confidence will be for each match.
Error Handling Page
The Error Handling page allows you to specify how errors should be handled when they happen.
There are three options available.
- Fail on error
- Fail on unmatched records (Since v25.2)
- Redirect rows to error output
- Ignore error
When the Redirect rows to error output option is selected, rows that failed to write to the Premium Lookup Component will be redirected to the 'Error Output' output of the component. As indicated in the screenshot below, the blue output connection represents rows that were successfully written, and the red 'Error Output' connection represents erroneous rows. The 'ErrorMessage' output column found in the 'Error Output' may contain the error message that was reported by the server or the component itself.
Performance
Lookup from a reference table can be a performance-intensive process, especially with large datasets and fuzzy matching. The following information can be used to help address performance issues:
- Exact match filters perform much better than fuzzy match filters; rows are compared for exact matches before any fuzzy matching is attempted. If you are able to add any exact match filters to your premium lookup component performance will improve.
- When using a fuzzy match filter the higher the similarity threshold you set, the better the performance will be (and the fewer matches you will get). A high similarity threshold allows potential matches to be eliminated more quickly.
- The MatchingPerformance setting determines the balance between fuzzy match quality and performance and can be very useful to achieve desired levels of quality and performance. This property is a value between 0 and 1. It defaults to 0.75 for the fuzzy match comparison type and uses an asymptotic scale, so small changes will have a bigger impact as they approach 1 and a smaller impact as they approach 0. If you are experiencing slow performance, especially with long strings (greater than 15 characters) try changing this value to something higher, such as 0.8 or 0.9. Each of the fuzzy lookup types has a default matching performance value that best suits that type of data.
- If your performance is good, and you would like better fuzzy matching precision, you can try lowering the MatchingPerformance value for a field. This will be especially useful for very short string fields (less than 8 characters). Try setting this value to 0.66 or 0.5 for improved fuzzy matching precision and lower performance.