Data is everywhere, and your business will most likely obtain data from numerous sources in different formats. These formats may even include data tables saved in PDF format. If the table is not too large or complex, you might be able to copy the information and keep it in a spreadsheet or text file. However, if the table is complex, runs across numerous pages or even has misaligned cells, you have few solutions available other than tracking down the source data. Add to that the possibility that the table you are looking to extract from is part of a larger PDF document that contains multiple tables and other content. You would have a significant challenge on your hands.
With the SSIS Premium PDF Source component from KingswaySoft, you can easily overcome the challenges and extract tabular data from PDF files with ease. Our Premium PDF Source component also provides features that make it flexible in detecting tables and working with header and row data. Let's show you how.
Demonstration Data
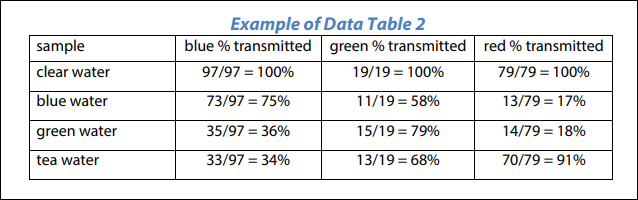
For the purpose of our post, let's use the below table, which we will read from a PDF file. The file consists of multiple tables, and we will be working with Table 2, as shown.
To demonstrate how the SSIS PDF Source component works, we will create a data flow to extract data from a PDF file and write it to a database table. To achieve this, we will need to use our:
- Premium PDF Source component to read the data from the PDF file, and,
- Premium ADO.NET Destination component to write data into a database, with additional options to Update, Delete and even Upsert data.
Both these components are available in our SSIS Productivity Pack.
Reading Table Data with the Premium PDF Source component
The first step is to identify the PDF file we will be working with. Our Premium PDF Source component can read a PDF file from many storage locations. These include accessing the file from your local computer, you can use our Connection Managers to connect to several sources, including FTPS/SFTP, Amazon S3, Azure Data Lake Storage, Dropbox, Hadoop, SharePoint, and so much more. For a complete list of available connection managers, visit our Premium PDF Source Component Help Manual.
We will be using a local file path to select the PDF file we will work with. Next, specify the table detection settings to define how the tables are detected. Under the Configure Table Detection settings, check whether you will need to combine tables across pages, skip empty rows and how you want to deal with misaligned cells. Next, select the table you want to work with using the Locate Table Strategy. Since the table we are considering has Headers which will be used in the output as field headers, we have enabled the Table Contains Column Names option and identified the Header Row Index. Additionally, in our example, actual cell data starts in the second row, so we chose 2 for the Data Start Row Index. The Read to End option is enabled to read all rows till the end.
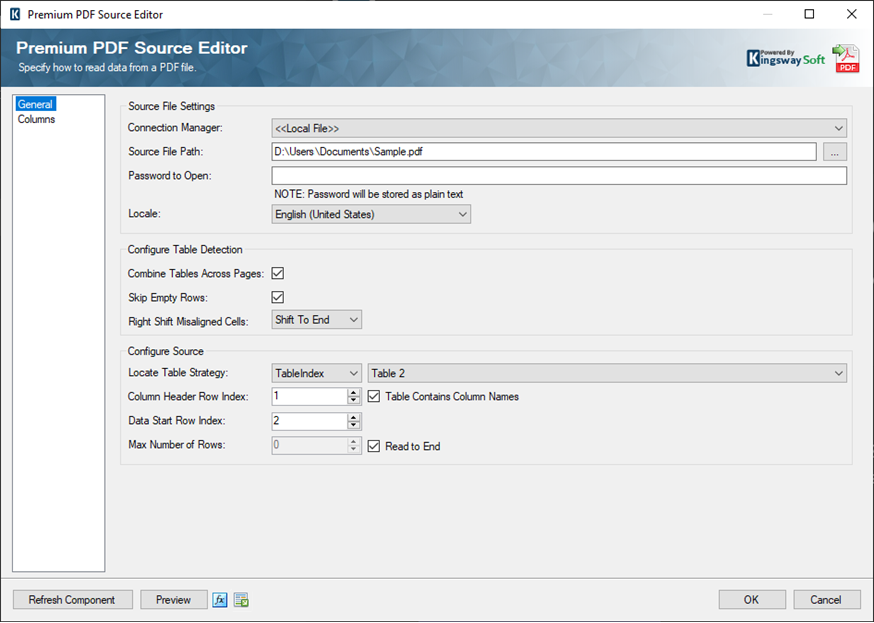
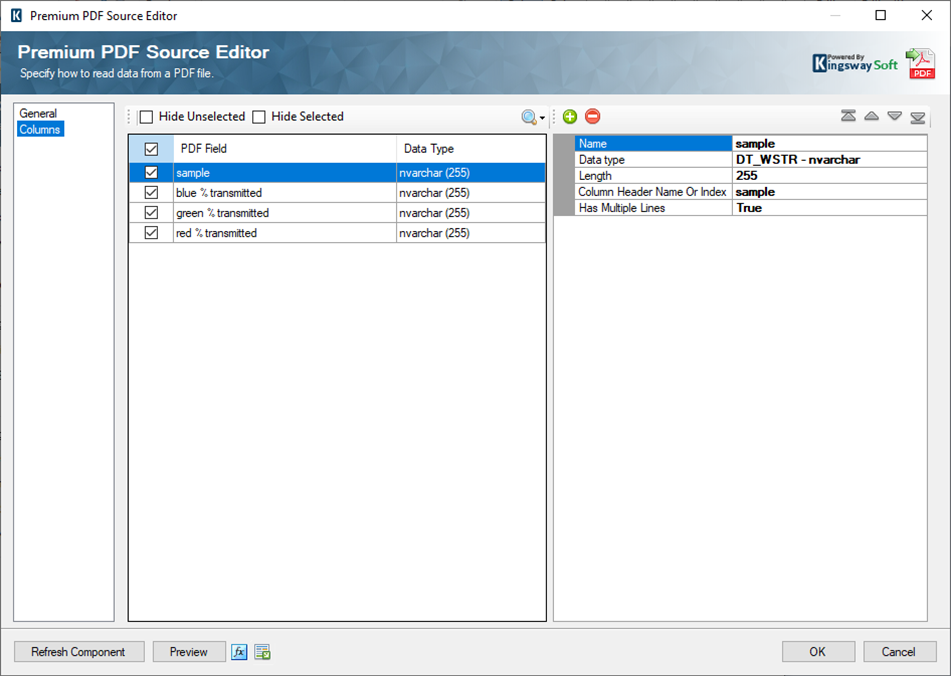
With the General page configured, head over to the Columns page to verify the table data you will be working with. Make sure to check that the Column Headers are correctly detected. The right-hand grid allows you to change the column name and datatype properties as required.
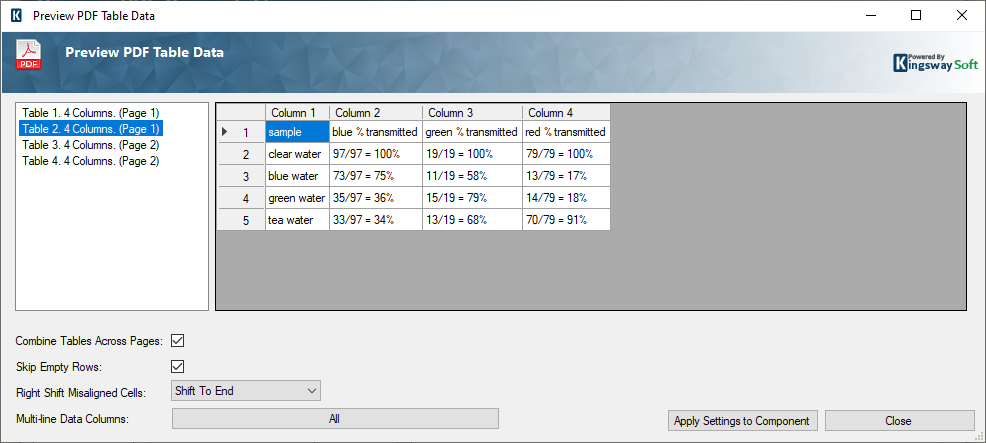
Click the Preview button to see the selected table. Preview will also display additional detected tables within the PDF file. This feature can help confirm the right table is selected, primarily if the file consists of identical or similar tables.
Writing PDF Table Data to a Database
With the PDF Source component configured, it's time to connect the output to a Premium ADO.NET Destination component linked to the required database table. In our example, we are connected to a SQL Server database and have mapped the columns accordingly. For productivity-enhancing purposes, we have chosen to work with the Upsert action for our demonstration. Upsert is beneficial when working with new data and old data that needs to be updated. Upsert will check if a row already exists based on a specified matching criterion. If it does exist, the component will update that row. If it does not find a match, it will create a new row. The action is handled within a single destination.
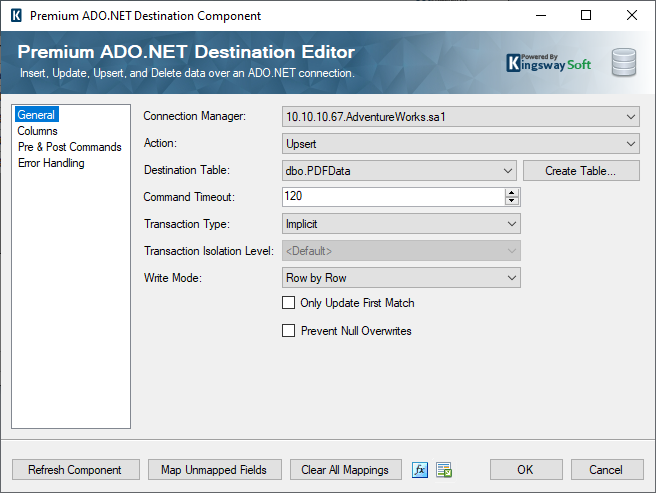
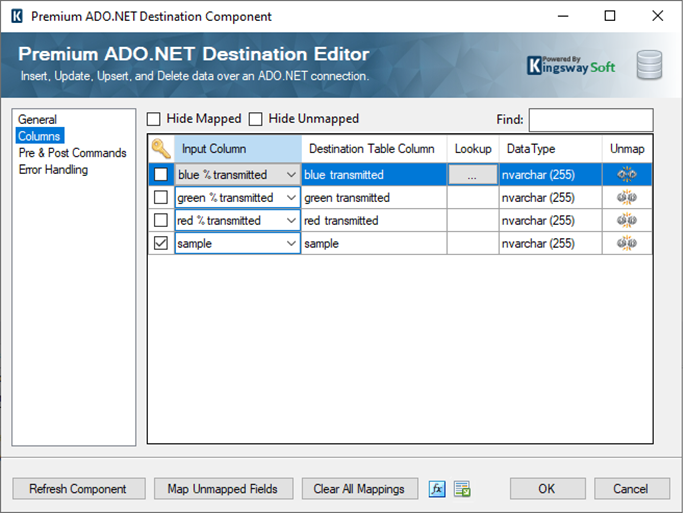
On the Columns page, use the drop-down lists to map the fields from the Premium PDF Source component to the destination database's appropriate columns. With all fields mapped, click OK to save the configuration.
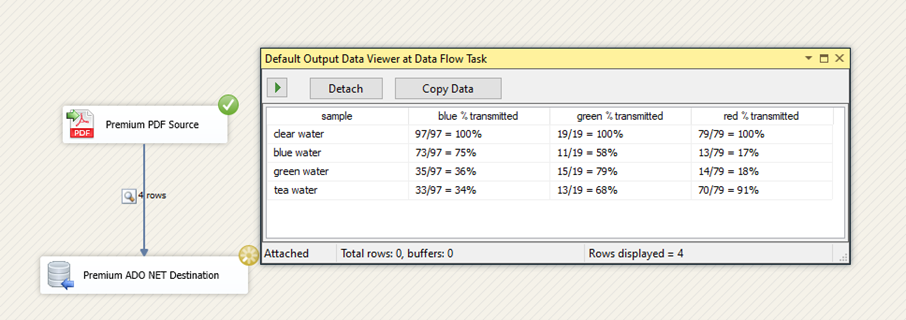
We are all set to execute the task. Enabling a data viewer in the data flow path, as shown below, will confirm the correct parsing of the PDF data.
Closing Note
With a simple setup, extract PDF table data with ease using our Premium PDF Source component, our latest offering from our 2020 Release Wave 2. Powered by the SSIS engine, extract data from PDF files and write the data to any application or database system, including a Service API or a flat-file like Excel. Once the design is ready, schedule the package to run automatically as often as required using an SQL Agent Job or any other scheduling tool that executes SSIS packages.
All the components used in this blog post are available in our SSIS Productivity Pack. Our SSIS Productivity Pack is a premium collection of SSIS component add-ons to increase SSIS productivity. With over 250 premium and unique SSIS components, developers can facilitate rapid ETL development without any custom scripting.