With GDPR now in full effect, many businesses are still working to implement processes to ensure compliance. While it is important to have accurate customer data within all production environments, for non-production environments this is not always essential. In this way, one method that can be employed to ease GDRP compliance is to remove personal data from all non-essential environments.
In order to maintain the data structure from production but remove personal data from the environments, SSIS can be used as a performant method to automatically mask sensitive data.
In this blog post we will cover two scenarios you can use to hide personal data from a data source to assist with GDPR compliance.
First we will cover how to mask non-essential data already within the environment. Afterwards we will cover what you can do you keep any new sensitive data from entering the environment.
To assist with GDPR compliance we will be using Data Anonymizer, this is an SSIS add-on component part of SSIS Productivity Pack. This component provides an easy method to mask data while maintaining data structure. Using this component you are able to select the columns you would like to mask so that those columns in each row are replaced with random sample data. The component supports several anonymization types, for example real client names, email addresses, GUIDs, etc. can be replaced with dummy client names, email address, GUIDs, etc. to help keep the data structure while masking the true values.
Anonymizing Existing Data
In our first example we will be masking data already in our non-production environment. To do this, we will create a new SSIS project and connect to our target system. For this scenario you can use any data source whether the data is in a database or an application. For our example we are going to be working with a SQL database as our target system.
Once you have your connection established, you can create a Data Flow Task and configure your source. When you configure your source, be sure to select all fields you would like mask in the environment and deselect any fields that do not need to be modified, or which you do not need in order to perform update matching later on.
In our example we’re retrieving from a Contacts table, we have deselected 3 fields which do not contain personal information we need to mask.
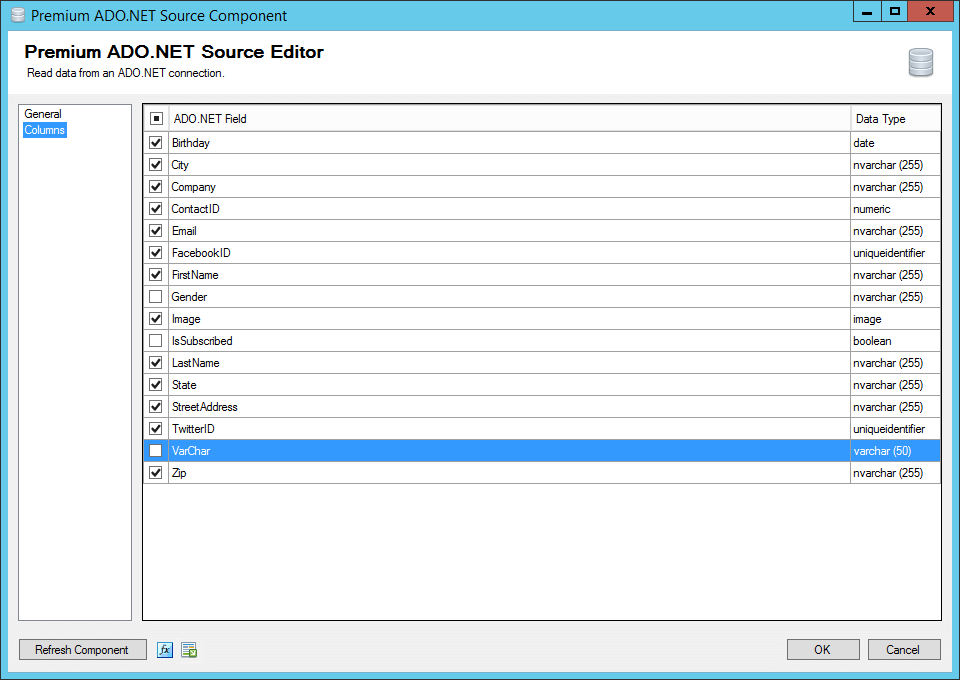
When we write back to the database later, we will be mapping based on the ContactID, as such we have selected to retrieve this field as well even though we will not be masking this field.
Now that we have all the data we want to mask selected, we can configure the fields for masking. As mentioned we will be using Data Anonymizer component to handle this for us. We can drag out the Data Anonymizer onto our design surface and connect our source to it. When we launch the Data Anonymizer editor, we will see all the fields we enabled for output from our source with the Anonymization Type set to Ignore.
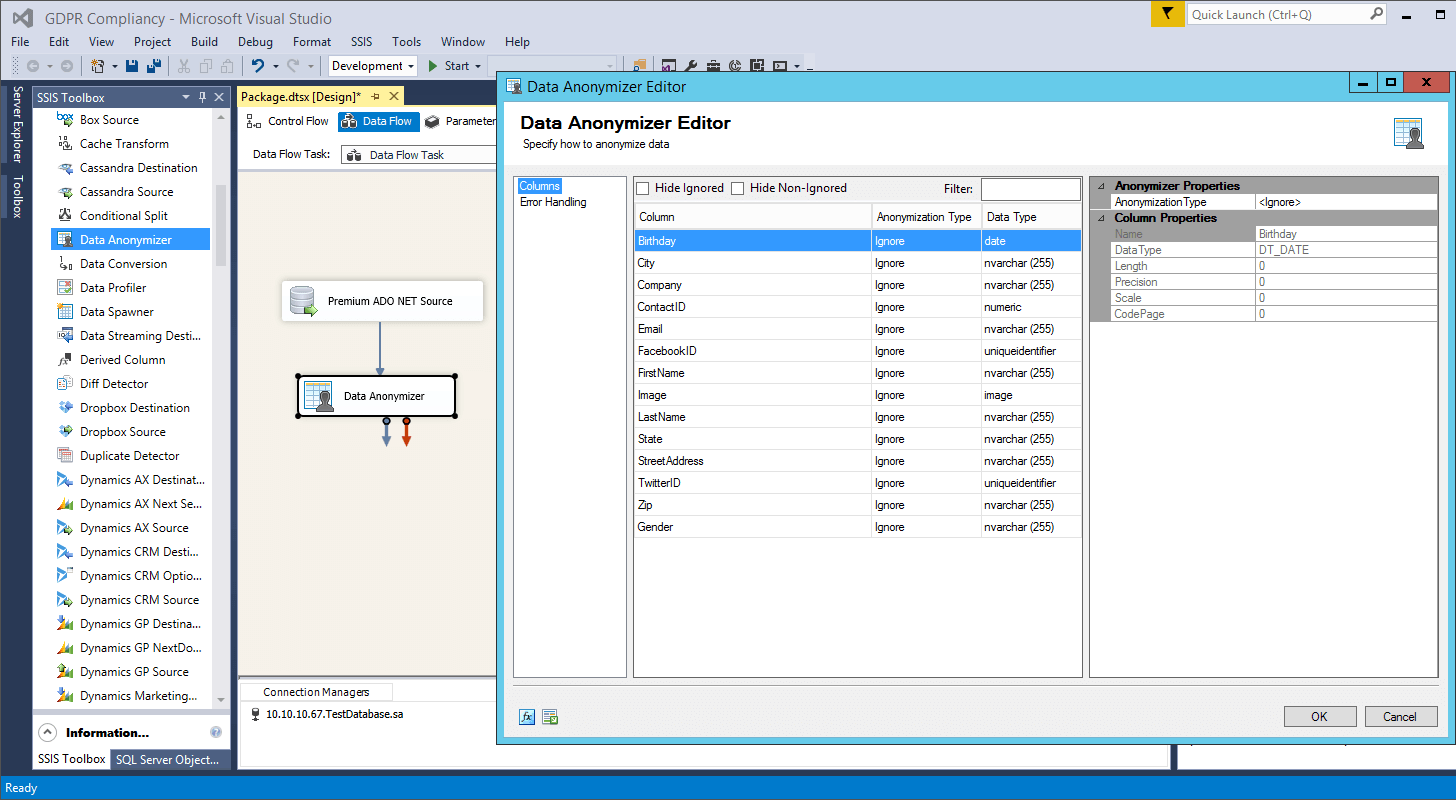
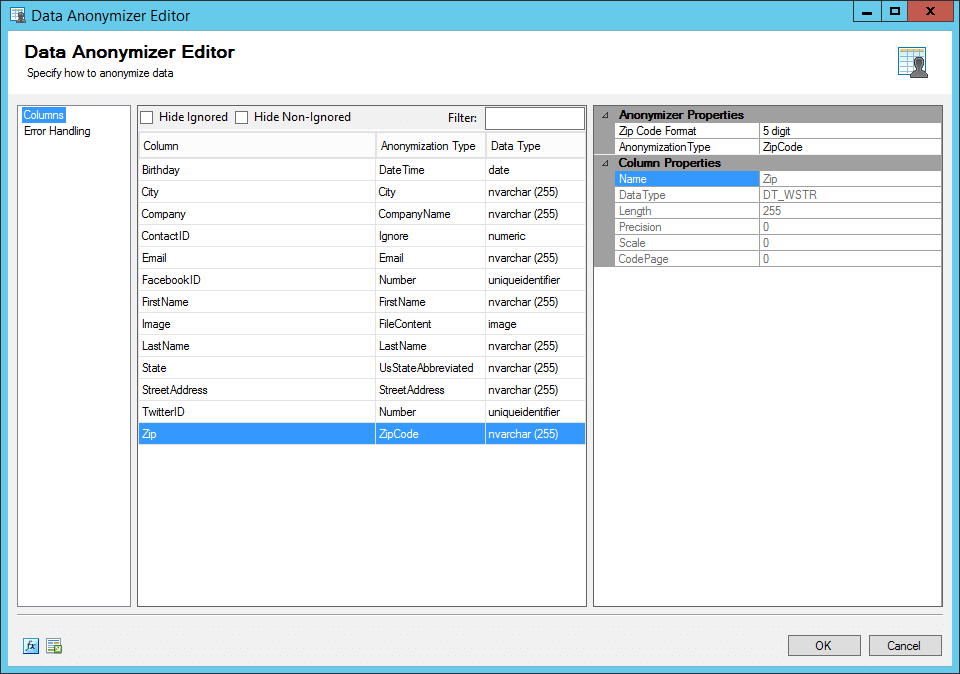
Data Anonymizer includes 30 different Anonymization Types including a custom option. You can view the full list of Anonymization Types and their descriptions on our help manual. Most personal information fields will have an Anonymization Type available already and you will simple need to select if from the drop-down in the Anonymizer Properties on the right. Some anonymization types will have additional properties you can configure to better match your true data structure such as defining the length of a generated zip code. Below we have configured each field to the appropriate Anonymization Type except ContactID which we have left as Ignore as we need to maintain this value for our mapping later on.
With our component configured, we can now set the data to write back to the target. This should be fairly straight forward to configure, we will be overwriting the current data and replacing it with the newly anonymized data.
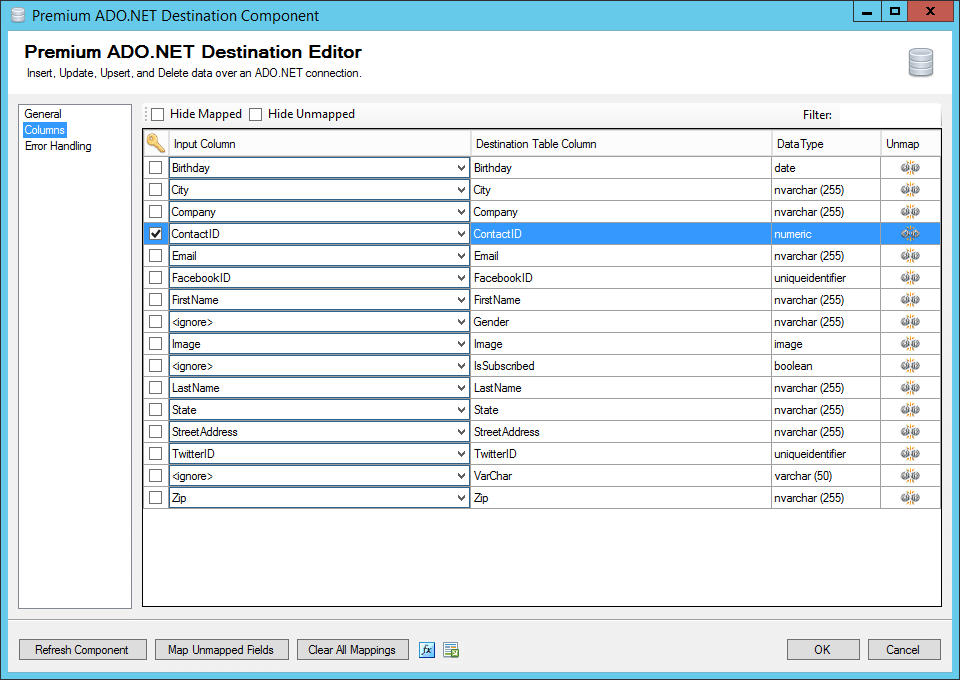
In our example we are using Premium ADO.NET Destination to update our database.
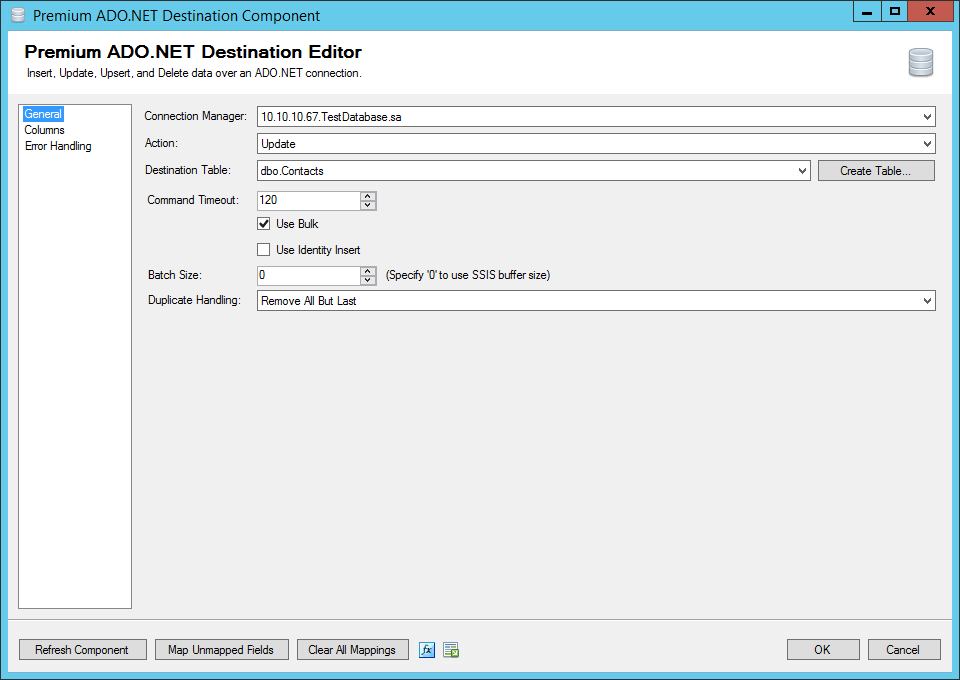
And we have selected ContactID as our key field to perform the update matching on.
We can now save this component and run our package. In the result of our example, all the contact information in our database will be overwritten with new random generated data. Personal information such has names, emails, addresses will be removed from our system and replaced with fake vales. This way we’re maintaining the structure of our data but removing non-essential values from the system so that we now only need to be concerned with the data in our production environment when it comes to GDRP compliance.
Below is a sample contact record, the "Before Anonymization" column is the true values which were previously in the system, the "After Anonymization" column is the result after our anonymization. Notice the highlighted rows are the same in both columns, these are the rows we did not select an anonymization type for and have left as is, ContactID (green) is the column we performed our update matching on when we were writing to our target server.
| Column | Before Anonymization | After Anonymization |
|---|---|---|
| Birthday | 01/01/1980 | 11/7/1952 |
| City | New York | West Darion |
| Company | KWS Industries | Customer-Focused Systematic Groupware |
| ContactID | 000001 | 000001 |
| John.smith@kwsindustries | [email protected] | |
| FacebookID | 26843592615 | 28878785408 |
| FirstName | John | Autumn |
| Gender | Male | Male |
| Image | <photo of John> | <replacement image> |
| IsSubscribed | True | True |
| LastName | Smith | Hoppe |
| State | NY | FL |
| StreetAddress | 656 Main St. | 0411 Muriel Trail |
| TwitterID | 648762 | 14239 |
| VarChar | False | False |
| ZIP | 10001 | 86485 |
Using Anonymization in On-Going Data Synchronization
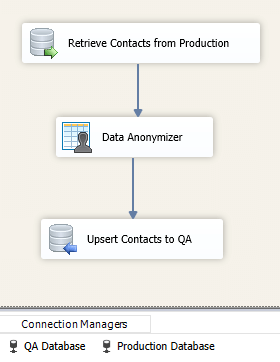
Now we want to keep this compliancy in place, this is a very straightforward process with a similar set-up to what we just did. In our second example, we are going to open up our existing SSIS package which we schedule to move data from our production environment into non-production. Every time we retrieve data from our production environment, we will add a Data Anonymizer before writing to our non-production environment. This will ensure data is always masked before entering a non-production environment so we never need to be concerned with sensitive data on our other systems.
Closing Notes
In this example we used a SQL Server database as our source and destination, this same strategy can be used for virtually any other application or database system. The Data Anonymizer component will accept any data input and can output the masked data to any output. For further reading we recommend checking out the blog post from Gustaf Westerlund, on how he is using Data Anonymizer to mask data in non-production Dynamics 365 CE instances. In his blog post he covers some specific situations when working with Dynamics 365 CE/CRM data.
It is important to note data anonymization cannot be undone, once a target has been replaced with anonymized data there would be no way to recover the data without a system backup or by re-importing the data from another environment. We recommend using caution before executing your task to ensure you are connected to the intended environment and you are overwriting the correct fields.
This is just one strategy you can utilize SSIS for to aid in GDPR compliance. What tricks are you currently using SSIS for to aid in GDPR? Let us know in the comments.