Similar to how we had shown how Snowflake Bulk load feature can be used to load huge data sets in a previous blog post, we have our Amazon Redshift Destination components that supports bulk load of data to the Redshift tables. The performance improvement to a very significant level is the major advantage of this feature. In this blog post, we will be discussing about the bulk loading capabilities of the Amazon Redshift Destination component that is available in our SSIS Productivity Pack, utilizing the features provided by the Amazon Redshift API.
In here, the staging location would be Amazon S3 location. Therefore, you could utilize our Amazon S3 components that is also a part of our SSIS productivity pack.
Connecting to the Data Source
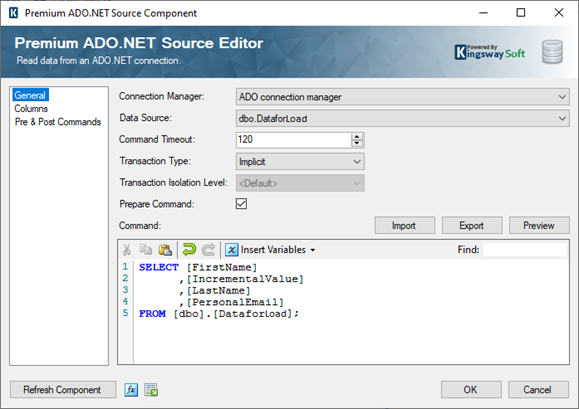
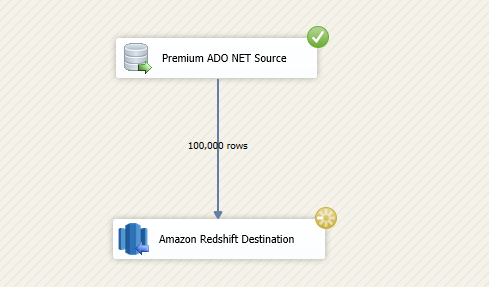
Consider the example below, in which we have a database table that consists of 100,000 records. For a regular load, this may take a while depending on the SSIS buffer settings and other performance factors, however, by using the bulk load feature in Amazon Redshift Destination component, we will now demonstrate how this can be done instantaneously. First, we use a Premium ADO.NET Source component in order to read from the SQL Server table. In the Source component, the ADO connection manager can point to your database, and the Data Source can be chosen to be the required table. If you wish to work with a particular set of records, you could even provide a Command to have a where clause, but in this case, we are considering the entire table.
Configuring the Amazon Redshift Destination component
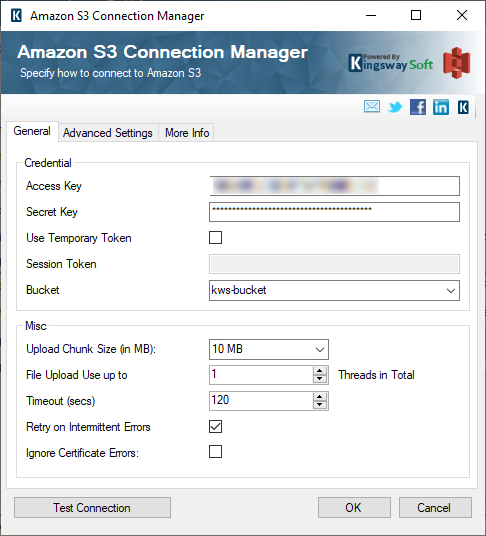
Once we have the Source component setup, you would need to configure the Amazon Redshift Destination component. In order to work with the bulk load feature, as we had mentioned, you would need a cloud storage Amazon S3 location as staging. Therefore, you would first need to create an Amazon S3 Connection manager. By right clicking on the “Connection Manager” section in VS SSDT, you can choose the Amazon S3 connection manager and configure it as shown below.
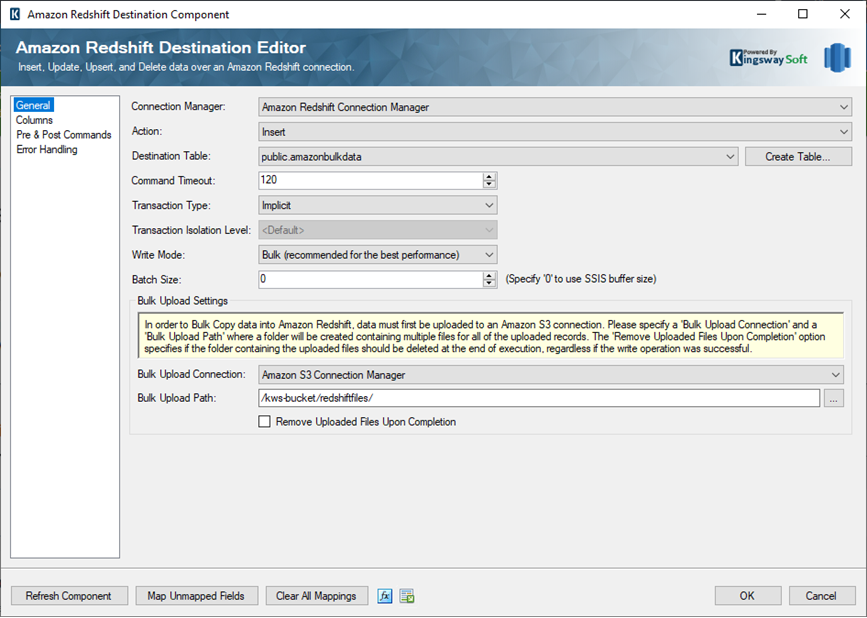
Once you have the Amazon S3 connection manager ready, you could start configuring the Amazon RedShift Destination component. Choose the "Connection Manager" and select the action. You can select the rest of the Database, Schema, and the Destination table. If you do not have a Destination table yet created, then our Amazon RedShift Destination component has the “Create Table” button, which would help you create one instantly.
Once you click on the button, the page below will open. In which the create table command is already populated, and the columns would be having the name and datatype depending on the metadata from the upstream Source component. Once you have modified the names, as per your requirement, you can click on “Execute Command” and you would see that the table is created and chosen in the “Destination Table” field in the Amazon RedShift Destination component.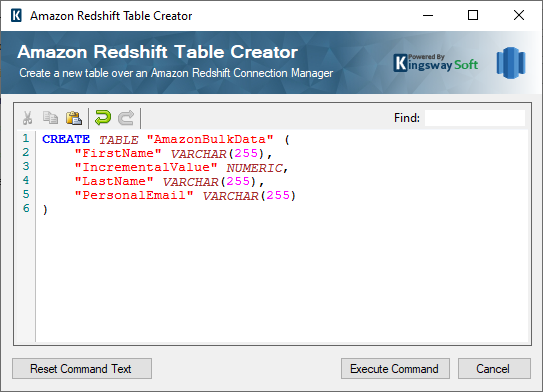
After the Destination Table is selected, you can then choose the Bulk Upload Connection Manager. This would be the connection manager pointing to the staging location. Since we are using Amazon S3 location for this, you can use the same connection manager we created in the previous steps, and then navigate to the path in S3 location by clicking on the ellipsis (…) button. There is an option “Remove Uploaded Files Upon Completion”, when enabled, would remove the data files that are created in the staging location. Please note that for the sake of demonstrating how the files are populated in the storage location, we have disabled this option. Next, you can choose to provide the batch size. This would determine how the files are created and how many rows to be written to each data file getting created in the staging location. We have specified the batch size as zero, so that the SSIS buffer size would be automatically be used. In the columns page of the Destination component, you can map from the input Source columns to the Destination Table columns.
Once you have the above configured, you can start execution. You would see that the Bulk load feature is much more efficient than a regular load. Even though our example data set is for 100,000 records, millions of records could be processed like this.
Once the task has run, since we have the option “Remove Uploaded Files Upon Completion” disabled, you would see the files populated in the Amazon S3 location that you had chosen.
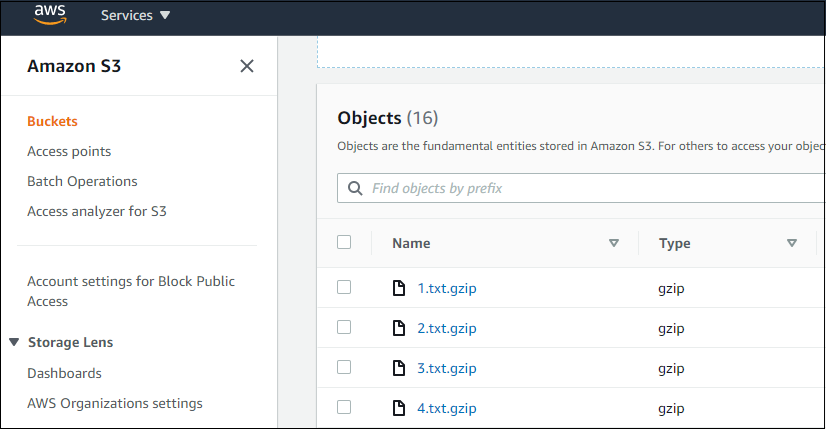
Please note that if the option to remove the files upon completion is enabled, these files would have been removed upon execution was successfully completed.
Closing Notes
In conclusion, the bulk writing feature in KingswaySoft's Amazon Redshift Destination Component can be used to work with large data loads leveraging Amazon S3 as intermediate cloud storage. This should offer significantly better performance than trying to insert one row at a time or even inserting records per batch. Otherwise, achieving an acceptable performance for moving large datasets to Redshift in SSIS would be challenging to implement by just using the out-of-the-box components.