Using the Decomposition Component
The Decomposition Component is a data flow transformation component that can be used to split the input values into multiple rows, and along with that, duplicate the other columns' values as well.
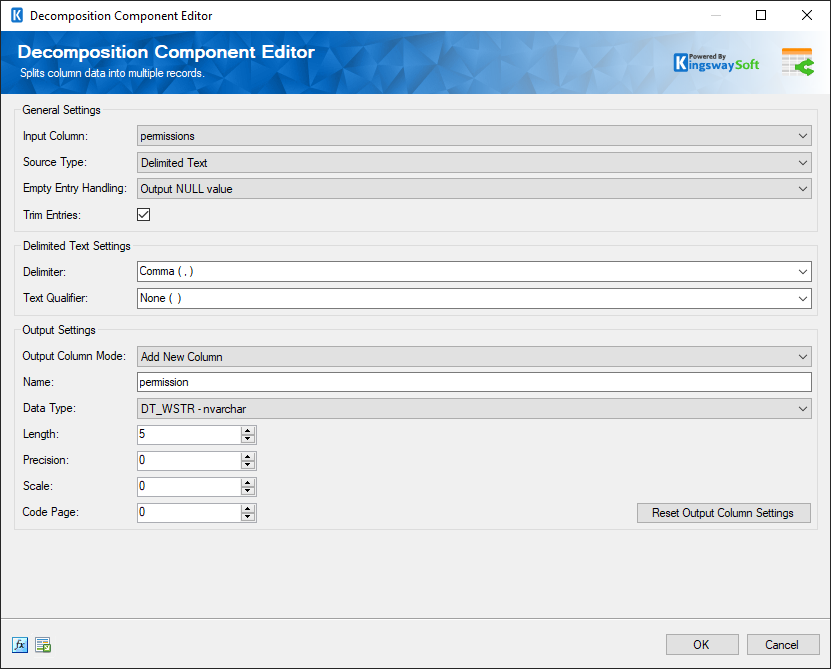
- General Settings
-
- Input Column
-
This is the input column that would be split and distributed.
- Source Type
-
There are three options to choose from:
-
-
- Delimited Text - If the input is in delimited text format.
- JSON Array - If the input is a JSON array.
- XML Elements - If the input is in XML format.
- Empty Entry Handling
-
There are three options to choose from on how to handle empty entries:
- Output NULL Value
- Output Default Values
- Skip Empty Entries
- Default Value (Only when Output Default Value is chosen as the Empty Entry Handling type)
-
The default value can be specified here for empty entries.
- Trim Entries
-
This option can be enabled if you wish to trim the entries.
-
- Delimited Text Settings (Only for Source Type as Delimited Text)
-
- Delimiter
-
You can choose the delimiter from the drop-down list:
- Newline (\n)
- Carriage Return (\r)
- Semicolon ( ; )
- Colon ( : )
- Comma ( , )
- Tab (\t)
- Vertical Bar (|)
- Text Qualifier
-
You can choose the text qualifier from the following options:
- Double quote ( “ )
- Single quote ( ‘ )
- Tick ( ` )
- None ( )
- Output Column Settings
-
- Name
-
Specify the name of the output merged column.
- Data Type
-
Choose the datatype of the output column.
- Length
-
Specify the length of the field.
- Precision
-
Specify the number of digits in a number.
- Scale
-
Choose the scale for the field.
- Code Page
-
Code page value can be chosen here.
- Reset Output Column Settings
-
This option can be used to reset the output column settings to default values.
- Expression fx Icon
-
Click the blue fx icon to launch SSIS Expression Editor to enable dynamic updates of the property at run time.
- Generate Documentation Icon
- Click the Generate Documentation icon to generate a Word document that describes the component's metadata, including relevant mapping, and so on.