Using the JSON Extract Component
The JSON Extract Component does something similar to the JSON source component, but it is a transformation component that receives JSON documents from an upstream component, extracts data from the received JSON documents, and produces column data for the SSIS pipeline.
Document Designer Page
The Document Designer page allows you to build the design of the document you are trying to extract or import the design from an existing document.
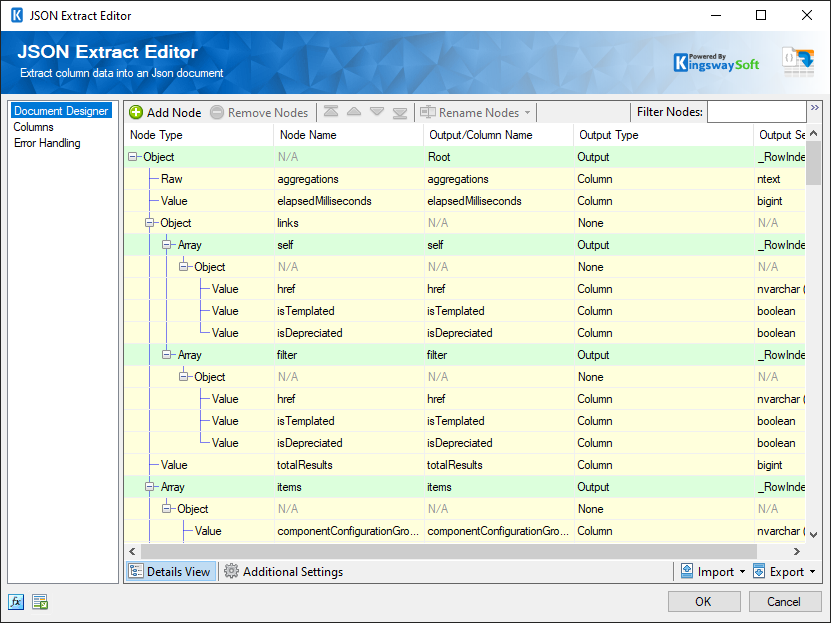
The Document Designer includes the following two tabs:
- Details View.
- Additional Settings.
In the Details View tab, the top part of the page is used to manually configure the nodes in the design:
- Add Node: This button will add a new node to your Document design.
- Remove Nodes: This button will remove a node from your Document design.
- Direction buttons: These buttons can be used to rearrange the position of the nodes.
- Rename Nodes: This option allows you to specify how the node name should be represented.
-
- Use Qualified Names: When this option is selected, the output/column name will be set to the full qualified node name based on the node location in the document.
- Use Short Names: When this option is selected, the output/column name will be set to the given Node Name directly.
-
Filter Columns: This option allows you to show or hide certain Columns in the grid.
- Show Basic Columns: When this option is selected, only basic columns will be shown in the grid.
- Show All Columns: When this option is selected, all available columns will be shown in the grid.
- Filter Nodes: This option allows you to filter the list of nodes shown in the grid by typing a keyword in the textbox.
The Details View grid consists of:
-
Node Type: This option allows specify the type of the Node in your document design. There are four options available:
- Array
- Object
- Value
- Raw: This type can be used when trying to retrieve data under a node exactly as it is in the document.
- Node Name: The Name of the Node in the document.
- Output/Column Name: The name which will be set for the output or the column of a node.
- Is Repeated: This option allows you to specify if a node is repeated within a document. (Available when Show All Columns is selected)
-
Output type: The type of output for a node, available options are:
- Column
- Variable
- Property Name As Column Value
- Key Value Pivot (since v20.1)
- Output Settings: This option allows you to specify the settings of each output such as the datatype of Value Node Types.
In the Additional Settings tab, you would find the following options:
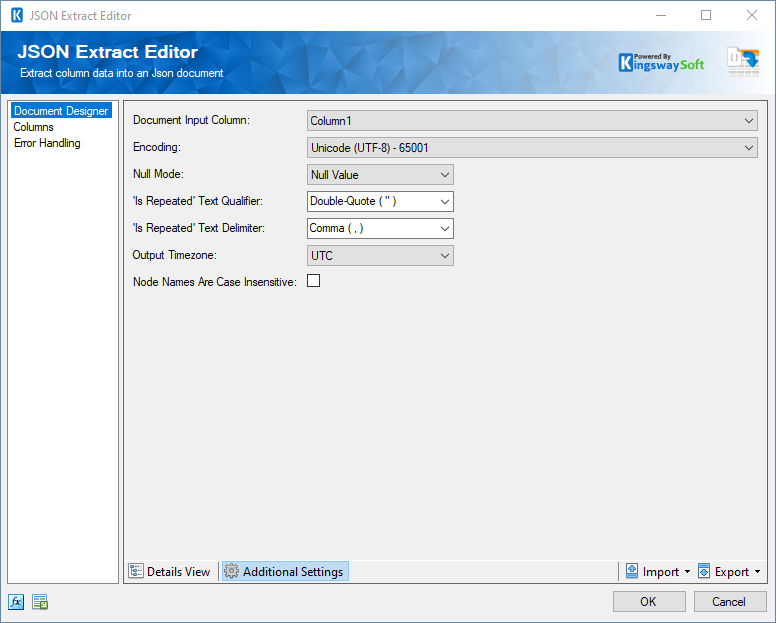
- Document Input Column: This option allows you to specify the input column that contains the JSON data to extract.
- Encoding: The encoding of the document that will be retrieved.
- Null Mode: This option allows you to specify the handling of Null values.
-
'Is Repeated' Text Qualifier: This option allows you to specify the
Text Qualifier used in a document when the
Is Repeated property is set to
True for one or more nodes. There are four options available:
- Double-quote(“)
- Single-quote (‘)
- Tick (`)
- None
-
'Is Repeated' Text Delimiter: This option allows you to specify the
Text
Delimiter used in a document when the
Is Repeated property is set to
True for one or more nodes. There are seven options available:
- Newline (\n)
- Carriage Return (\r)
- Semicolon (;)
- Colon (:)
- Comma (,)
- Tab (\t)
- Vertical Bar (|)
-
Output Timezone: The
Output Timezone option lets you specify how all datetime fields should be retrieved. Available options are:
- UTC
- Local
-
- Node Names Are Case Insensitive: This option allows to specify that the node names are case insensitive.
- Import
-
This option allows you to import the design of your document from one of the following three sources:
- Designer Settings: Import the design from an existing .designer.settings file.
- JSON (Local File): Import the design based on a JSON file on your local file system.
- JSON Schema (Local File): Import the design based on a JSON Schema file on your local file system.
- Export
-
Designer Settings: This option allows you to export the current document design to a .designer.settings file which can be used later to import the same design in a different component.
- Expression fx Icon
-
Click the blue fx icon to launch SSIS Expression Editor to enable dynamic updates of the property at run time.
- Generate Documentation Icon
-
Click the Generate Documentation icon to generate a Word document that describes the component's metadata including relevant mapping, and so on.
Columns Page
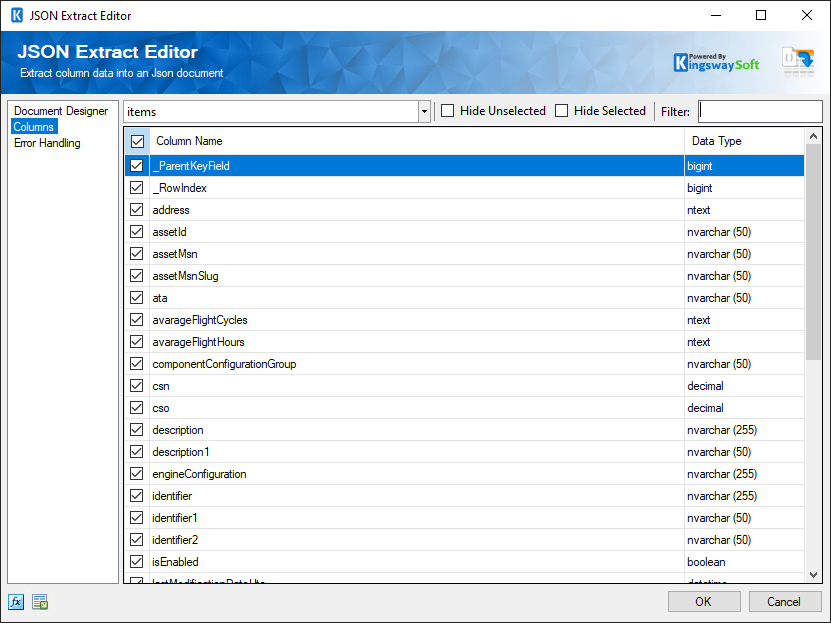
The Columns page of the JSON Extract Component shows you the available columns based on the settings on the Document Designer page.
-
On the top left of the grid, you can see a checkbox, which can be used to toggle the selection of all available fields. This is a productive way to check or uncheck all available fields. The Columns Page grid consists of:
- Include Field Checkbox: A checkbox that determines if the field will be available as an output column.
- Column Name: Column that will be retrieved from the document.
- Data Type: The data type of this field.
- Hide Unselected Fields
-
When the Hide Unselected Fields checkbox is checked unselected output columns will be hidden.
- Hide Selected Fields
-
When the Hide Selected Fields checkbox is checked used selected columns will be hidden.
- Filter
-
The output columns that are visible can be filtered by entering text in the Filter text box.
There are a couple of special columns to take note of:
- _RowIndex: This column contains the current count of this output node.
- _ParentKeyField: This column contains the value of this record's parent key field.
Error Handling Page
The Error Handling page allows you to specify how errors should be handled when they happen.
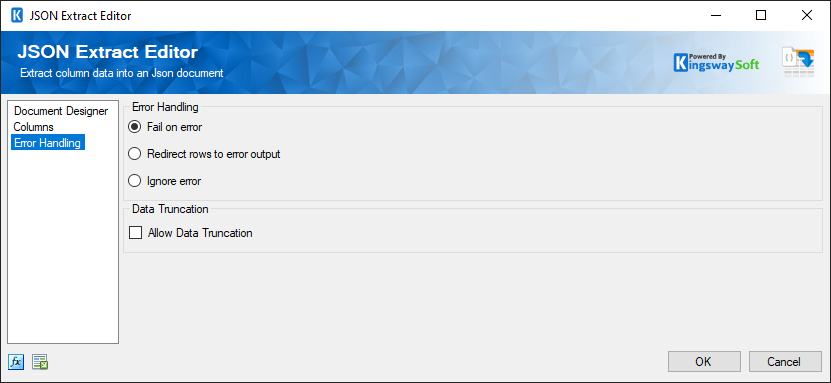
There are three options available:
- Fail on error
- Redirect rows to error output
- Ignore error
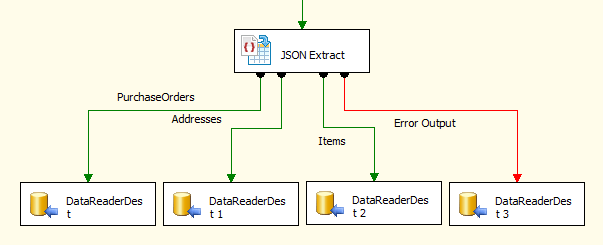
When the Redirect rows to error output option is selected, rows that failed to be sent will be redirected to the 'Error Output' output of the Transformation Component. As indicated in the screenshot below, the green output connection represents rows that were successfully sent, and the red 'Error Output' connection represents erroneous rows. The 'ErrorMessage' output column found in the 'Error Output' may contain the error message that was reported by the component.
Allow Data Truncation
This option will apply to all output columns. However, in order to enable data truncation on a certain column, then you would disable this option and enable data truncation in the column's properties using the component's Advanced Editor.