Google BigQuery Destination Component
The Google BigQuery Destination component is an SSIS data flow pipeline component that can be used to write data to Google BigQuery. There are three pages of configuration:
- General
- Columns
- Error Handling
The General page is used to specify general settings for the Google BigQuery Destination component. The Columns page is used to manage columns from the upstream component. The Error Handling page allows you to specify how errors should be handled when they occur.
General Page
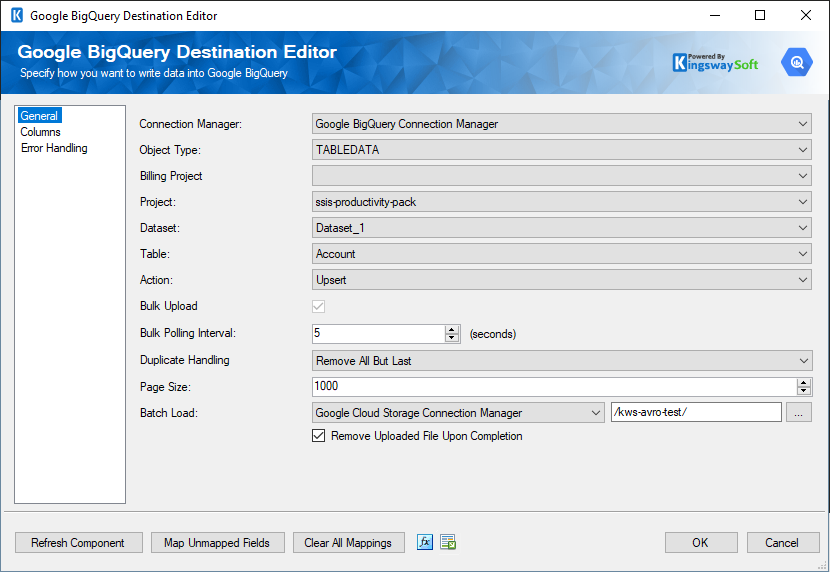
The General page allows you to specify general settings for the component.
- Connection Manager
-
The Google BigQuery Destination Component requires a connection. The Connection Manager drop-down will show a list of available connection managers.
- Object Type
-
The Object Type option allows you to specify the Google BigQuery Object you want to work with. There are four types available:
- DATASET
- JOB
- TABLE
- TABLEDATA
- Action
-
Depending on the Object Type you have specified, there are different Actions available for different Object Types:
- Insert: DATASET, JOB, TABLE, and TABLEDATA
- Update: DATASET and TABLE and TABLEDATA
- Patch: DATASET and TABLE
- Delete: DATASET and TABLE and TABLEDATA
- Cancel: JOB
- Upsert(since v21.2): TABLEDATA
- FullSync(since v21.2): TABLEDATA
- Delete Contents
-
The Delete Contents option specifies whether you want to delete all the tables in the dataset. If you leave this option unchecked and the dataset contains tables, the request will fail.
Note: This option is only available to the DATASET object.
- Billing Project(since v22.1)
-
The Billing Project option allows you to specify which billing project is for executing bulk jobs.
Note: This option is only available to the TABLEDATA object and when the Bulk Load option is enabled.
- Project
-
The Project option allows you to specify which project you want to write to Google BigQuery. The drop-down will present a list of all available projects in your Google BigQuery.
Note: This option is only available to the TABLEDATA object.
- DataSet
-
The Data Set option allows you to specify which dataset you want to write to Google BigQuery. The drop-down will present a list of all available datasets in the specified project.
Note: This option is only available to the TABLEDATA object.
- Table
-
The Table option allows you to specify which table you want to write to Google BigQuery. The drop-down will present a list of all available tables in the specified dataset.
Note: This option is only available to the TABLEDATA object.
- Page Size
-
The Page Size option allows you to specify how many records to send in a request.
Note: This option is only available to the TABLEDATA object.
- Template Suffix
-
If the Template Suffix option is specified, Google BigQuery will treat the destination table as a base template, and inserts the rows into an instance table named "{destination}{templateSuffix}". BigQuery will manage the creation of the instance table, using the schema of the base template table. For more details, please check here for considerations when working with template tables.
Note: This option is only available to the TABLEDATA object.
- Ignore Unknown Values
-
If the Ignore Unknown Values option is enabled, Google BigQuery will accept rows that contain values that do not match the schema. The unknown values are ignored. It is unchecked by default.
Note: This option is only available to the TABLEDATA object.
- Skip Invalid Rows
-
If the Skip Invalid Rows option is enabled, the component will insert all valid rows to the specified table, even if invalid rows exist. It is unchecked by default, which causes the entire insert action to fail if any invalid rows exist.
Note: This option is only available to the TABLEDATA object.
- Insert As JSON
-
The Insert As JSON option specifies whether the input should be one single input column that takes the value in JSON format from the upstream component.
Note: This option is only available to TABLEDATA object.
- Bulk Upload
-
Bulk Upload checkbox specifies whether you want to perform a bulk load operation into a Google BigQuery database, the data is first uploaded to a temporary Avro file on Google Cloud Storage and from that temporary file, the data is loaded into the destination table.
-
Note: This option is only available to the TABLEDATA object.
- Bulk Polling Interval
- This field determines the frequency (in seconds) at which to poll the status of the job to determine if it has been completed. The default is 5 s.
-
Note: This option is only available to the TABLEDATA object.
- Duplicate Handling(since v21.2)
-
The Duplicate Handling option allows you to specify how input duplicates should be handled when the Bulk Upload option is enabled on Update/Upsert/Delete/Full Sync actions. There are three options available:
- Remove All But Last
- Remove All But First
- Ignore
- Bulk Load
-
Specify the Google Cloud Storage connection manager and the file path to store the temporary Avro file.
- Remove Uploaded File Upon Completion
-
When Remove Uploaded File Upon Completionis checked, then the batch files in the intermediate storage location will be deleted once all files have been loaded to the final destination table. If you uncheck this box, the batch files will remain in the intermediate storage location. Note: this does not delete records from the Source.
- Refresh Component Button
-
Clicking the Refresh Component Button will bring up a prompt for you to confirm the refresh. After clicking “Yes”, it will remove any existing columns and add all columns from upstream pipeline components.
- Map Unmapped Fields Button
-
By clicking this button, the component will try to map any unmapped attributes by matching their names with the input columns from upstream components.
- Clear All Mappings Button
-
By clicking this button, the component will reset (clear) all your mappings in the destination component.
- Expression fx Button
-
Click the fx button to launch SSIS Expression Editor to enable dynamic updates of the property at run time.
- Generate Documentation Button
-
Click the Generate Documentation button to generate a Word document that describes the component's metadata including relevant mapping, and so on.
Columns Page
The Columns page of the Google BigQuery Destination Component allows you to map the columns from upstream components to the Google BigQuery Fields.
On the Columns page, the grid displayed that contains four columns as shown below.
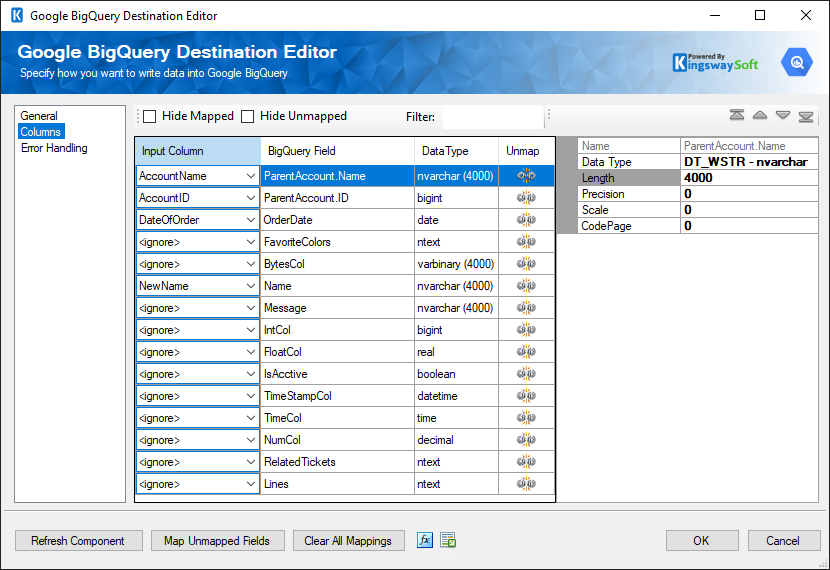
- Input Column: You can select an input column from an upstream component for the corresponding Google BigQuery Field.
- Google BigQuery Field: The field that you are writing data to.
- Data Type: This column indicates the type of value for the current field.
- Unmap: This column can be used to unmap the field from the upstream input column, or otherwise it can be used to map the field to an upstream input column by matching its name if the field is not currently mapped.
- Properties window for the field listed. These values are configurable:
- Name: Specify the Column name.
- Data Type: The data type can be changed according.
- Length: if the data type specified is a string, the length specified here would be the maximum size. If the data type is not a string, the length will be ignored.
- Precision: Specify the number of digits in a number.
- Scale: Specify the number of digits to the right of the decimal point in a number.
- CodePage: Specify the Code Page of the field.
- Arrows: Move the fields to a desired location in the file.
Error Handling Page
The Error Handling page allows you to specify how errors should be handled when they happen.
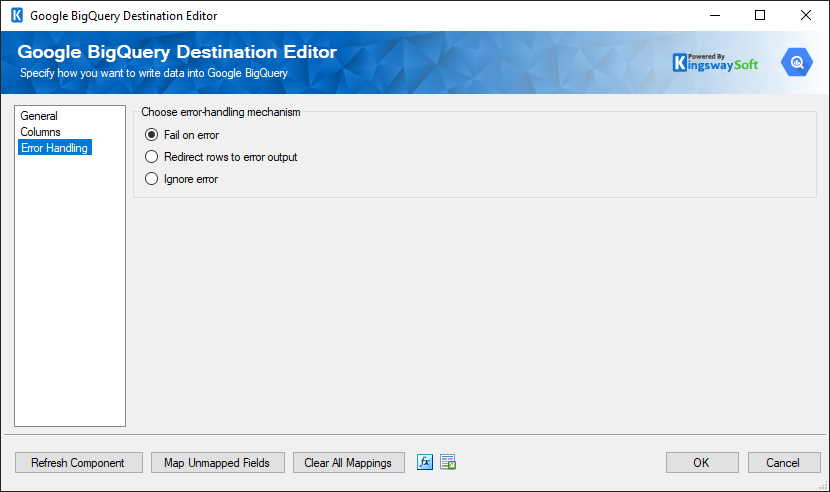
There are three options available.
- Fail on error
- Redirect rows to error output
- Ignore error
When the Redirect rows to error output option is selected, rows that failed to write to the Google BigQuery will be redirected to the ‘Error Output’ output of the Destination Component. As indicated in the screenshot below, the blue output connection represents rows that were successfully written, and the red ‘Error Output’ connection represents erroneous rows. The ‘ErrorMessage’ output column found in the ‘Error Output’ may contain the error message that was reported by the server or the component itself.