Advanced Topics
- How do I maximize the throughput when writing data to Microsoft Dynamics?
-
The easiest way to achieve a better writing performance when working with Microsoft Dynamics 365 is to use a Batch Size along with the Multi-threaded writing (available since v9.0) which are two single configurations in the CRM destination component. However, it's important to choose the right combination of Batch Size and the number of threads used to achieve the best possible performance.
When choosing a batch size, please use the following guidelines.
- Whenever possible, use a batch size in the CDS/CRM destination component, which can substantially reduce the number of HTTP round-trips in the ETL process for the same amount of data to be processed, which would, in turn, render some improved performance in writing to Dynamics 365 CE/CRM system.
- For all typical CRM entities, we generally recommend using a Batch Size of 10 which seems to be offering the best performance with a proper thread number specified in combination. The maximum allowed batch size is 1000, however, it does not work in the way that the higher batch size will always render better performance. For this reason, we don't typically recommend using a very high batch size, as it would carry the risk that the service call may time out more frequently.
- When working with attachment entities (annotation, activititymimeattachment), we recommend using an even smaller batch size (1 to be absolutely safe) to avoid potential upload errors as there is a maximum payload allowed by Dynamics/CDS application. Such upload errors can be reported as a server busy error often the time.
We recommend enabling multi-threaded writing whenever possible. Without the option, the component would write one record (or one batch) at a time. When the option is enabled, it will write multiple records (or batches) to the Dynamics/CDS server simultaneously, which can provide a substantially improved write performance. Generally speaking, the higher thread number you use, you should expect better performance. However, that is not guaranteed to be always true, as all servers are limited to their capacity in terms of how many simultaneous requests they can process at the same time. Use the following general guidelines when choosing a thread number:
- For on-premises Dynamics 365 / CRM server installation (including most IFS configurations), you can choose as high a number as your application and database servers can sustain the load. Most Dynamics 365/CRM servers should easily sustain a load of 30 to 50 concurrent threads without problems. How many threads can be used would depend on your server's capacity and configurations among other factors such as your network latency and client computer resources. When multi-threaded writing is enabled in the CRM/CDS destination component, you should watch the usage of CPU and memory resources on the application and database servers, and make adjustments as necessary depending on whether the usage is too high or too low on the server. You want to make sure that you are using a number that does not overload your servers.
- For CDS or Dynamics 365 online instances, the number of threads that you can use largely depends on the server-side throttling that Microsoft has put in place. Generally, we recommend you start from 10 concurrent threads. You might be able to work with a higher thread number to gain better performance, you may try and see. However after the thread number has been increased to a particular number (the exact number always depends on various factors in terms of your networking conditions and many other things), you will see a stop of further performance improvement, which is where you should stop. Keep in mind, your CDS/CRM online service calls are generally throttled, there is no reason to further increase the thread number once you are seeing those throttling messages reported by our software in the SSIS log. Due to the server-side throttling, it is recommended that you should always run the latest release of our software, as Microsoft might introduce new server-side throttling behaviors from time to time, only our latest release would provide you with the most recent strategies to work with such throttling behaviors gracefully. At least you should be looking at using our v11.1 release or above.
Please note that the multi-threaded writing feature is only available since our v9.0 release. For all prior releases, you will have to use the SSIS BDD Component, which is less flexible, less scalable, and requires more effort to maintain and configure.
In addition to the multi-threaded writing and Bulk Data Load API, there are also many other things that can be used to improve the performance of the CDS/CRM destination component. In case you work with Dynamics 365 CE/CRM on-premises servers, you would start by first looking at those options that can be used to improve the performance of your Dynamics 365 CE/CRM server and database server, such as upgrading the server capacity, increasing the network bandwidth, etc. Other than that, the following are some additional options that you could look into.
- Whenever possible, try to minimize the number of CDS/CRM fields that you want to write to.
- You want to make sure that you have the lowest possible network latency to your Dynamics 365 CE/CRM server. When targeting CDS or Dynamics 365 online, you may consider running the integration on an Azure SSIS-IR or an Azure Windows Server virtual machine (either temporary - if it is a one-time migration, or permanently - if it is an ongoing integration) that is in the same data center as your CDS or the Dynamics 365 instance, as this would offer the lowest possible network latency which helps with integration performance.
- When using manually specified fields as the matching fields for the Update or Upsert actions, you want to make sure the selected matching fields are covered by database indexes. This can be done by creating custom indexes in Dynamics 365 CE/CRM database (this is a fully supported practice) if it is an on-premises installation. For CDS or Dynamics 365 online environment, you may raise a support ticket to do so. If creating custom indexes is not possible (say your online support ticket gets rejected), you can add those matching fields to the Find Columns of the entity's Quick Find View, in which case the Microsoft Dynamics 365 CE/CRM server will automatically create indexes for them. Of course, when doing so, those fields will be used when quick find is performed in the application UI. Also, note that there might be a delay between the time that you save the quick find view and when the indexes are actually created.
- The Upsert action (except when the Alternate Key matching option is used) involves an extra service call that queries the target system by checking for the existence of the incoming record, which has a cost associated in terms of its impact on your overall integration performance. If you have a way to do a straight Update or Create, it would typically offer better performance. However, in some cases, the benefits of using straight Create or Update action could be offset or justified by the "Ignore Unchanged Fields" option used with Upsert action, as when enabled, the option skips all unchanged fields which can help avoid firing some unnecessary plugins, workflows, or data audits on the server side. In the case that no fields are changed at all for the incoming record, the entire row will be skipped. Both situations can help improve integration performance which, in some cases, can be very significant, particularly when working with a slowly changing source system. Note that the extra service call also applies to the situation when the Update action is used along with manually specified fields being selected for Update matching.
- When using the text lookup feature, the two different cache modes offer different performances, choose the right option based on your integration scenario. The general guideline is when the lookup entity contains a relatively small number of records, but you are processing a large number of records for the primary destination entity, you should be using the Full Cache option. Otherwise, if you are only processing a small number of records for the destination entity, but the lookup entity has a very large number of records, then the Partial Cache will give you a better performance.
- When any impersonation fields (createdby, modifiedby, or impersonateas) are mapped, please consider having the input data sorted by such impersonation fields to help achieve better performance. This is necessary when the batch size is greater than 1. When doing so, the incoming rows will be better organized in terms of batching, we automatically group records based on the input value of those fields, which is why having it sorted is better than a scrambled input. Note that the impersonateas field is only applicable to principalobjectaccess entity at this moment.
- Plugins or workflows usually have a certain degree of performance impact on your data integration. Poorly designed plugins or workflows could severely affect your integration performance. Try to compare the performance before and after enabling them, in some cases, you might have to revisit their design to make sure that best practices are applied in your custom code.
- You may leverage those Process Optimization options (available since our v20.2 release) in our CRM/CDS destination component to disable plugins, audits, and/or workflows while data load is happening. If you are using v20.1 or lower, you may consider manually disabling them during the load and you can re-enable them after the data load is done.
- The "Remove Unresolvable References" option involves checking the existence of all lookup values, which can be very expensive, it should be avoided unless absolutely required.
- Avoid relying on the Duplicate Detection option if you can.
If working with a Dynamics 365/CRM on-premises installation, you may consider the following additional techniques or optimizations:
- Before a large data import, try to prepare your database by resizing its file to an estimated final size after the import.
- Make sure you have turned off the CRM trace log when running your integration/migration jobs.
- In the case that you have complex workflows or asynchronous plugins that are adversely affecting your integration performance and you don't really have a way to further improve them, you should consider setting up a (or more) dedicated asynchronous server while turning off the asynchronous service on your application server(s).
- If you have a multi-node cluster for your on-premises deployment, you can use CDS/CRM connection manager's ServerUrl property (this used to be named under the CrmServerUrl property) in its ConnectionString to specifically target a particular node within the cluster. In doing so, you can have multiple connection managers in the same package or project that target different nodes of the cluster, and you write to multiple destination components of the same configuration with different connection managers so that you are technically writing to multiple cluster nodes in parallel, which provides some additional performance improvement on top of multi-threaded writing.
- Watch out for the resource usage on your integration server, Dynamics 365 the CE/CRM server, and also the database server while running the integration (in case you are using CDS or Dynamics 365 online instance, you would have to raise a ticket to work with Microsoft online support team if you believe there might be an issue with your online servers), and check if any processes are consuming too many resources. You could use Windows server Performance Monitor if necessary.
- Make sure that the "Reindex All" maintenance job is configured and running properly, or otherwise create DB maintenance jobs to REBUILD or REORGANIZE indexes for your CDS/CRM database on a regular basis.
- Monitor your database server to see if there are any excessive DB locks.
It should be noted, the above list is not an exhaustive list of all the best practices. There are many other things to be considered that can improve your data flow performance. Also, we have tried to only focus on SSIS development practice. We will keep adding to the list when we come across something useful, you are always welcome to revisit this list at any time.
- When I use a SOAP 2011 endpoint, I run into an error stating that "An error occurred when verifying security for the message." What should I do?
-
Most likely the date and time of your systems that run SSIS and Microsoft Dynamics CRM are out of sync. You need to ensure that the time difference between the two systems is less than 5 minutes.
- I am getting an error saying "Metadata contains a reference that cannot be resolved: 'https://crm.dynamics.com/XRMServices/2011/Discovery.svc?wsdl'" when I try to list CRM organizations in the CRM connection manager. What's the problem?
-
This error occurs when you have entered the wrong discovery server URL.
- How do I specify lookup types when using the CRM destination component?
-
CRM entities often contain lookup fields that refer to more than one lookup entity. For example, the CRM contact entity has a lookup field called ownerid, which can take values from either systemuser or team entities.
In this case, when we write data to the CRM destination component, we need to provide not only the GUID value of the lookup field but also its type.
Using the above-mentioned sample, when we write data to the CRM contact entity, notice that both ownerid and owneridtype fields are available in the CRM destination component. ownerid will take a GUID value, while owneridtype accepts values that can be used to determine the lookup entity type. When providing values for a lookup entity type field (i.e. owneridtype), you can either specify the entity's name or its entity type code (an integer value).
If you plan to use the integer entity type code (also referred to as object type code), you should be aware of a few facts about how it works. Each CRM entity has an object type code in the system. For system entities, it would be an integer from 1 (account) to a maximum of 4 digits (9999). For custom entities, it is usually a number starting from 10,000. One thing you should be mindful of is that the custom entity's object type code could change from environment to environment after the customizations are promoted across environments. For this reason, we generally recommend you use the entity's name instead.
The type field usually has a name ending with "type", but it is not always the case. An example of such an exception is the objectid field from the annotation entity (CRM notes entity). There are two type fields that you can use, which are objectidtypecode and objecttypecode. You can use either one of them to specify the objectid field's lookup type.
The lookup type field is only needed when the lookup type cannot be determined by CRM metadata. If it is a straight 1:N relationship that involves only two entities (one parent entity and one child entity), you will not need to provide such types.
- What format of data do I expect to read from a CRM activityparty (partylist) field in a CRM source component?
-
Depending on the software version you are using, the output is different.
-
If you are using v5.0 or later versions, the output of an activityparty (partylist) field will be in JSON format, which consists of a list of parties. For each party record, there will be a PartyId which is a GUID, a Name which is the party's name, and a Type which indicates the party's entity type. The following is a sample of such output which consists of an account record and a systemuser record.
[ { "PartyId":"c2cb1adc-cec4-e311-80e0-7845c4c5c272", "Name":"ABC Inc.", "Type":"account" }, { "PartyId":"61f78159-c1ce-441e-9eb4-e4c84206d89f", "Name":"Joe Smith", "Type":"systemuser" }, ]Note: the actual output will be in a condensed format, and no line break or indentation is provided.
-
When using v4.1 or earlier versions, the output of the field will include a list of lookup values delimited by a semicolon(;). Each lookup value then consists of two parts divided by a colon(:), with the first part being the entity name, and the second part being the entity record's GUID. The following is a sample output of an activityparty field when v4.1 or earlier is used:
contact:76ff2c4b-eb64-e111-9222-002215d5e;systemuser:1e64836d-1c66-e111-a28e-0022cad5e
-
- How do I specify the input values for a CRM activityparty field in a CRM destination component?
-
When working with activityparty fields (or partylist fields), the CRM destination component takes two types of inputs:
-
JSON (since v5): The input of an activityparty field can be either one of the three modes:
-
GUID mode: You have all the primary key values in GUID format for all involved parties, such as
[ { "PartyId":"c2cb1adc-cec4-e311-80e0-7845c4c5c272", "Type":"account" }, { "PartyId":"61f78159-c1ce-441e-9eb4-e4c84206d89f", "Type":"systemuser" }, ] -
Text mode: You have the text value of the party records, and you use the Text Lookup feature to find the involved party's primary key value (GUID), such as:
[ { "Name":"ABC Inc.", "Type":"account" }, { "Name":"Joe Smith", "Type":"systemuser" }, ] -
Hybrid mode: You have a mix of GUID and text values as your input for an activityparty field, in which case you use Text Lookup for some party types, and pass in the primary key values (GUID) for other party types. For instance:
[ { "PartyId":"c2cb1adc-cec4-e311-80e0-7845c4c5c272", "Type":"account" }, { "Name":"Joe Smith", "Type":"systemuser" }, ]For this particular example, we use the Text Lookup feature to handle the lookup of the "systemuser" entity, but we are passing in the GUID value directly for the "account" entity in which case we choose the Opt Out option for the "account" entity in the activityparty field's Text Lookup configuration window.
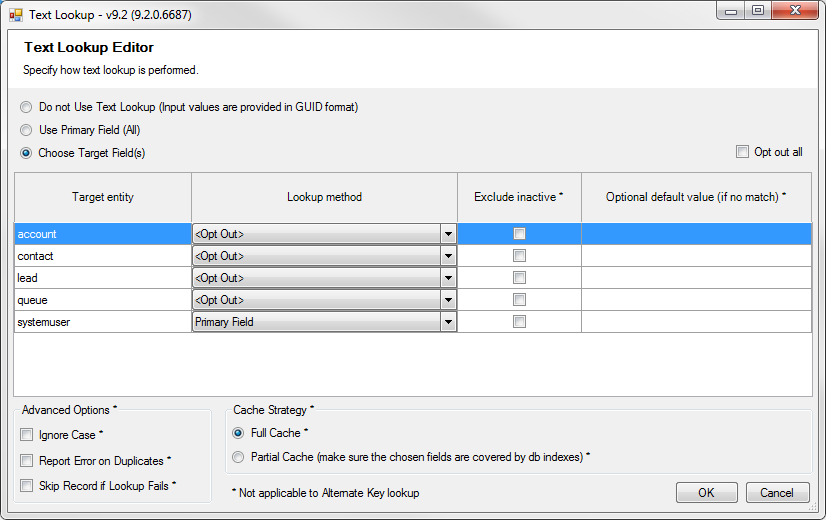
Note: when using JSON format input, the line breaks and indentations shown in the above samples are not required.
-
-
Delimited Text: As an alternative option to the JSON format input, you can use delimited text as the input for the activityparty field. The Delimited Text input needs to be constructed using semicolon(;) and colon(:) delimiters. The following is a sample value that you can provide for an activityparty field.
contact:76ff2c4b-eb64-e111-9222-0022cad5e;systemuser:1e64836d-1c66-e111-a28e-015ecad5e
The value first uses a semicolon(;) character to concatenate lookup values, each lookup consists of two parts, divided by a colon(:), with the first part being the entity name, and the second part being the entity record's GUID.
For the email entity, CRM also takes email address directly, in which case you can either use the above format, or specify the party list by concatenating them using a semicolon(;) as a delimiter, such as:
[email protected];[email protected]
Note: when using Delimited Text format, there is no way to perform text lookup, you would have to always pass in primary key values in GUID format.
Note: Delimited Text is the only supported format if you are using v4.1 or prior.
-
- When trying to create email attachments using the activitymimeattachment entity, if I map the attachmentid in the CRM Destination Component, the attachment does not get created.
-
When the attachmentid is mapped in the Destination Component, attachment records are not added to the attachment records. From the CRM SDK, the attachmentid field shows up as a writeable field, which is why you can see this in the CRM Destination Component, however, you should avoid mapping this field.
- How do I do lookup for CRM records?
-
You may consider using one of the following techniques.
- You can use Text Lookup offered by our toolkit (since v2.0) to look up the record using text values.
- Use an SSIS Lookup or Fuzzy Lookup component if you have access to the CRM database directly.
- Use an SSIS Merge Join component to join the data that you read from a CRM source system and a destination system. Reading from CRM data is generally fast, so using a CRM source component to read data from CRM before doing the join would generally outperform a CRM lookup component if it were provided. After the Merge Join, you would typically have a Conditional Split component that you can use to route joined rows to different outputs depending on whether the Merge Join component produces a match.
- When we need to load data into CRM for more than one entity, how should we design the data flow tasks to load data into CRM so that the lookup references can be properly resolved?
-
When we have more than one entity to be loaded into CRM, a general practice is to load the dependent entity first. For example, say we are going to load data for two entities, EntityA and EntityB. EntityA has an N:1 relationship to EntityB, or in other words, EntityA has a lookup field to EntityB. In this case, we should load EntityB first, and then load EntityA. So the data flow that writes data for EntityB should proceed with the data flow of EntityA.
- I am getting an error message saying "The type of 'parentcustomerid' lookup field was not specified", what I should do to fix this issue?
-
This error happens to the CRM lookup field that points to more than one entity, parentcustomerid is one such CRM field for the account entity.
To address this particular error, you must provide input for the corresponding type field of the concerning lookup. The type field should be typically in the format of lookupfieldname + "type". In the case when the lookup field is parentcustomerid, its type field is parentcustomeridtype.
The input for such lookup type field can be either the lookup entity's name (string) or its type code in integer format. In the case when the lookup field is parentcustomerid, the input value can be either "account" or "contact" in string format, or the lookup entity’s type code which is 1 (for "account") or 2 (for "contact").
Similarly, when you work with the ownerid field, you would need to provide input for the owneridtype field. The input value can be either "systemuser" or "team" in string format or its CRM entity type code which is 8 (for "systemuser") or 2 (for "team").
Note: the entity name will only work for SOAP 2011 service endpoint (or later). If you are using SOAP 2007 (CRM4) or SOAP 2006 (CRM3), the input value has to be the type code in integer format.
- Can I modify the connection manager's Service Endpoint option from one version to another?
-
Yes, but you need to carefully manage the change, with the assistance of the "Refresh CRM Metadata" functionality that we added since v2.0. The reason being different service endpoints have incompatible metadata. Making changes to a service endpoint often causes problems for the CRM Source Component or the CRM Destination Component that uses the connection manager if the component's metadata is not properly updated.
For this reason, we have disabled the ability to change the connection manager's service endpoint from the CRM Connection Manager window directly, after it has been created. However, it is still possible to do it from the connection manager's Properties window.
The following are the procedures that you can follow to change the connection manager's service endpoint.
- Highlight the connection manager, and press F4 to bring up its Properties window if it is not shown yet.
- Make changes to its ServiceEndpoint property in the Properties window, by changing to the desired service endpoint.
- Exit Visual Studio (this is necessary since the connection manager often has its properties cached).
- Re-launch your Visual Studio (BIDS or SSDT-BI) environment, re-open your SSIS package, and double-click the connection manager.
- In the CRM Connection Manager window, re-list your CRM organizations, and re-select your CRM organization. Make sure you can successfully connect using the new service endpoint when you click the "Test Connection" button.
- Open each CRM source or destination component in your SSIS package, and click the "Refresh CRM Metadata" button to update the component's metadata to the new service endpoint. Click the "OK" button to save the component.
Make sure that you have done the last step for all CRM source or destination components that you have within your SSIS package, otherwise, your dataflow task will most likely fail.
- How do I work with documentbody field of the annotation entity?
-
The documentbody field is a special field in the CRM annotation entity, which is used to store the binary content of a filestream. Due to its binary nature, it is encoded before being stored in the CRM database. When you read this field, you will get an encoded string using base64 encoding. When you write data to this field, you can either encode the file content using base64 encoding, or you can use an Import Column component to read the file as a DT_IMAGE field, in which case the component will automatically handle the encoding before writing to the CRM server.
- Why don't I see the CRM entity that I need to work within the list?
-
CRM entities have a display name, and also a physical name. Often, we tend to use the entity's display name for our communication purposes. However, the display name cannot uniquely identify a CRM entity. For this reason, SSIS Integration Toolkit always uses a physical name to show the list of CRM entities (the same is true for CRM fields). For instance, the CRM Order entity's physical name is called salesorder, the Note entity is called annotation, and the Case entity is called incident. Another special case that should be noted is for custom entities, their physical name usually starts with a prefix. Keeping this in mind, you should be able to find the entity that you need to work with.
Also, there could be cases when you need to read data from some special CRM entities that do not show up in the list. In this case, you can use the FetchXML option to achieve your purpose.
- I am getting an error saying "Microsoft.SqlServer.Dts.Pipeline.DoesNotFitBufferException: The value is too large to fit in the column data area of the buffer". What's the problem?
-
This error could happen to the CRM source component and also the CRM OptionSet Mapping component, it is generally related to the string length of the output values.
- If it is a CRM source component, it is usually caused by incorrect field metadata reported by the CRM server. To fix it, right-click the CRM Source Component, choose "Show Advanced Editor...", and then navigate to the "Input and Output Properties" page. Click "Output" (on the left) to collapse the subtree underneath it, find the offending field, and increase its Length property or change its DataType property to "Unicode Text Stream [DT_NTEXT]" (on the right), which should take care of the issue.
- If this error happens to a CRM OptionSet Mapping component, there are two possibilities:
- The output option label value has a longer length than its source. For instance, if your input source data is "Mailing" which has a string length of 7, your mapping component is trying to map this option to "Mailing Address", the new output value will have 15 characters that do not fit into the buffer of 7 characters, which would render this error. To fix it, right-click the OptionSet Mapping component, choose "Show Advanced Editor...", and then navigate to the "Input and Output Properties" page. Click "Output" (on the left) to collapse the subtree underneath it, find the field that you are mapping as the CRM OptionSet field, and increase its Length property (on the right), which should take care of the issue.
- In other cases, it might be caused by corrupted SSIS metadata of the OptionSet Mapping component. In this case, you can disconnect the OptionSet Mapping component from the upstream component, and re-connect it in order to re-establish the component's metadata.
- How can I parameterize CRM connection so I can connect to different CRM servers at runtime using the same CRM connection manager?
-
There are many ways to parameterize your CRM connection based on your deployment strategy.
One of the easiest options is to set the CRM connection manager's ConnectionString property dynamically using SSIS variable(s). Note that since v3.1, you can include Password and ProxyPassword in the ConnectionString.
- I am getting an error saying "System.Exception: CRM service call returned an error: The formatter threw an exception while trying to deserialize the message: There was an error while trying to deserialize parameter http://schemas.microsoft.com/xrm/2011/Contracts/Services:request. The InnerException message was 'Error in line 1 position 448. Element 'http://schemas.microsoft.com/xrm/2011/Contracts/Services:request' contains data from a type that maps to the name 'http://schemas.microsoft.com/xrm/2011/Contracts:ExecuteMultipleRequest'. The deserializer has no knowledge of any type that maps to this name. Consider changing the implementation of the ResolveName method on your DataContractResolver to return a non-null value for name 'ExecuteMultipleRequest' and namespace 'http://schemas.microsoft.com/xrm/2011/Contracts'.'. Please see InnerException for more details." What's the problem?
-
This problem happens to a CRM 2011 installation, the cause of the problem is, your CRM Destination Component's Batch Size is set to a value that is greater than 1 but you do not have Microsoft Dynamics CRM 2011 UR12+ installed. When you set your destination component's Batch Size property to a number greater than 1, the component will start to use CRM bulk data load API, in which case ExecuteMultiple messages will be used. However, the bulk data load API is a feature that is available only when you have CRM UR12+ installed. Please either change the Batch Size back to 1, or install UR12+ on your CRM server if that is an option for you.
- Why am I receiving a timeout error when I am using the Delete action in the CRM Destination Component?
-
Please note that using a high Batch Size setting may result in timeout errors within the CRM Destination Component. If you have Parental cascading behavior defined for your entity, when you try to delete the record, all the child records would be deleted too, which may take a long time. To avoid this issue, you should use a lower value for your Batch Size setting.
In version 6.1, the CRM Destination Component will try to detect if your target CRM system has Bulk API enabled. If it does, the Batch Size will automatically be set to 200 for any action. You should take extra precautions with the delete action - consider reducing your Batch Size setting if you receive timeout errors.
- When I specify the Upsert action with the Manually Specify option, why can't I see the checkboxes?
-
It is likely that you are on a very old version of our software and your DPI Setting is higher than 100%. You can fix this issue by lowering this setting to 100%, or you may manually enter the UpsertMatchingFields property using SSIS Properties window.
For some advanced integration topics that are not covered in this manual page, you should check out our online FAQ page which covers some specific integration scenarios, including:
- Frequently asked licensing questions
- Best practices and performance tuning
- How to work with CRM partylist fields
- Some frequently encountered errors
- and more...